
Hey there, future AI expert! 👋
If you’re looking to master the confusion matrix for Class 10 CBSE AI, you’re in the right place. Remember when you first heard “Confusion Matrix” in class and thought, “Wait, if I’m confused, is that the matrix or just me?”
Trust me, you’re not alone. This is THE most Googled Question.. Here’s the thing: Confusion Matrix isn’t confusing once you see it the right way.
By the end of this guide, you’ll be calculating Accuracy, Precision, Recall, and F1 Score faster than your classmates can open their calculators. This is the most comprehensive confusion matrix class 10 tutorial you’ll find – complete with real CBSE board exam questions and solutions. Promise.
What You’ll Learn in This Guide
By the end of this post, you will be able to:
- Build a confusion matrix from scratch — the way CBSE examiners expect, not just identify the boxes
- Calculate all four metrics — Accuracy, Precision, Recall, and F1 Score — from any given matrix, showing full working
- Explain which metric to use and why — the answer that separates a 2/2 from a 1/2 in your board exam
- Understand why accuracy can be misleading — the question that appears in nearly every Class 10 AI theory paper
- Apply these concepts in your Orange Data Mining practical — so your practical exam does not surprise you
Why Confusion Matrix Matters for Class 10 AI Board Exams?
📘 Class 10 AI (Subject Code 417) — Unit 3: Evaluation Metrics for Classification
This entire post maps to Class 10 Unit 3. The CBSE syllabus covers: train-test split, accuracy, error, precision, recall, F1 score, and the confusion matrix — along with three mandatory activities your teacher may include in your practical file. Theory weightage: this unit contributes questions in the 4–6 mark range in Part B of your board exam.
Board Exam Reality Check:
- 4-6 marks guaranteed in Theory paper (usually Q21 or Q22)
- 5 marks in Practical exam (Orange Data Mining evaluation)
- 5 marks in Viva (examiners LOVE asking about metrics)
That’s 14-16 marks just from understanding one concept. Worth your next 15 minutes, right?
What is a Confusion Matrix? (The Simple Answer)
The confusion matrix class 10 definition: A confusion matrix is a 2×2 table that shows how well your AI model is making predictions by organizing results into four categories.
Imagine you’re a doctor’s AI assistant. Your job is to predict if patients have diabetes or not based on their blood test results.
You test 100 patients. Here’s what happens:
- Sometimes you’re right: “Diabetes” → Actually has diabetes ✅
- Sometimes you’re wrong: “Diabetes” → Actually healthy ❌
- Sometimes you’re right: “Healthy” → Actually healthy ✅
- Sometimes you’re wrong: “Healthy” → Actually has diabetes ❌
A Confusion Matrix is just a 2×2 table that organizes these four outcomes.
That’s it. Seriously. Everything else is just fancy names for these four boxes.
The Four Magic Boxes: Understanding the Matrix
Let me break down each box using the diabetes example:
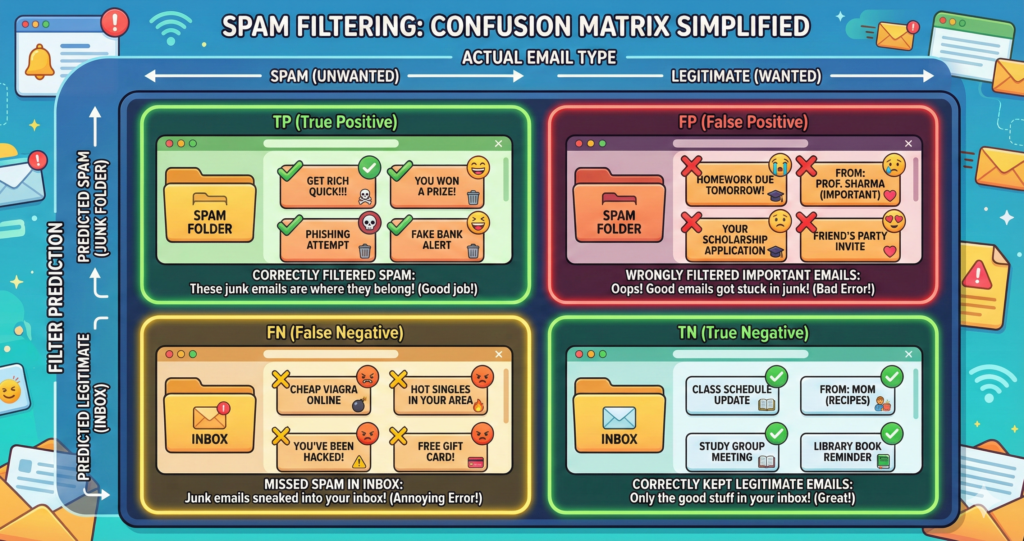
Box 1: True Positive (TP) ✅
What it means: You predicted “Diabetes” → Patient actually has diabetes Real-life: You correctly identified sick patientsThink of it as: You were right about the bad news
Example: Out of 100 patients, you correctly identified 30 diabetic patients. TP = 30
Box 2: True Negative (TN) ✅
What it means: You predicted “Healthy” → Patient actually is healthy Real-life: You correctly identified healthy peopleThink of it as: You were right about the good news
Example: Out of 100 patients, you correctly identified 55 healthy patients. TN = 55
Box 3: False Positive (FP) ❌
What it means: You predicted “Diabetes” → Patient actually is healthy Real-life: You scared a healthy person unnecessarily Think of it as: False alarm! (Also called Type I Error)
Example: You wrongly told 5 healthy people they have diabetes. FP = 5
Why it matters: Imagine getting a cancer diagnosis, panicking, telling your family… then finding out it was wrong. That’s False Positive.
Box 4: False Negative (FN) ❌
What it means: You predicted “Healthy” → Patient actually has diabetes Real-life: You missed a sick person (they go untreated!) Think of it as: You missed the danger (Also called Type II Error)
Example: You told 10 diabetic patients they’re fine (they won’t get treatment). FN = 10
Why it matters: This is often WORSE than False Positive. Missing a disease can be deadly.
How to Draw a Confusion Matrix (Step-by-Step)
The Standard Format:
Here’s how to structure it:
| PREDICTED: Positive | PREDICTED: Negative | |
|---|---|---|
| ACTUAL: Positive | TP (True Positive) ✅ | FN (False Negative) ❌ |
| ACTUAL: Negative | FP (False Positive) ❌ | TN (True Negative) ✅ |
Memory Trick 🧠
Top row (ACTUAL Positive): True comes first
- Top-left: True Positive (TP)
- Top-right: False Negative (FN)
Bottom row (ACTUAL Negative): False comes first
- Bottom-left: False Positive (FP)
- Bottom-right: True Negative (TN)
Diagonal = Correct predictions (TP and TN) Off-diagonal = Mistakes (FP and FN)
Filling Your First Confusion Matrix (Practice Example)
Scenario: A spam email filter tested on 200 emails.
- 80 emails were actually spam
- 120 emails were actually not spam (ham)
Results:
- Correctly identified 70 spam emails (TP)
- Correctly identified 100 ham emails (TN)
- Wrongly marked 20 ham as spam (FP) ← Your important emails went to spam folder!
- Missed 10 spam emails (FN) ← Spam reached your inbox
Let’s fill the matrix:
| PREDICTED: Spam | PREDICTED: Not Spam | Total | |
|---|---|---|---|
| ACTUAL: Spam | 70 (TP) ✅ | 10 (FN) ❌ | 80 |
| ACTUAL: Not Spam | 20 (FP) ❌ | 100 (TN) ✅ | 120 |
| Total | 90 | 110 | 200 |
Quick Check: TP + FN + FP + TN = 70 + 10 + 20 + 100 = 200 ✅
📗 Class 12 AI (Subject Code 843) — Unit 2: Data Science Methodology
Class 12 students: the confusion matrix is tested as part of Unit 2 (Data Science Methodology). Your CBSE practical activities explicitly require you to calculate Precision, Recall, F1 Score, and Accuracy from a given confusion matrix. The Python code to evaluate a model is assessed in practical only — see the Advanced Learners note below. Theory paper marks for Unit 2: 8 marks.
How Class 12 Uses the Confusion Matrix Differently
If you are in Class 12, you are expected to use the confusion matrix as a model validation tool within a data science project — not just as a standalone calculation exercise.
Here is what that means in practice:
Step 1 — You train a model (as part of your Capstone Project or using Orange Data Mining).
Step 2 — You evaluate it using the confusion matrix. Your CBSE practical activity asks you to compute all four metrics from the resulting matrix.
Step 3 — You justify your metric choice. A Class 12 answer should explain why you prioritised Recall over Accuracy (or vice versa) based on the problem context. This is what moves your answer from 6/8 to 8/8.
What Class 12 examiners look for that Class 10 examiners don’t: The Class 12 marking scheme expects you to connect metric selection to the real cost of errors in your chosen domain. A student who says “I chose Recall because False Negatives are dangerous” scores higher than one who only states the formula.
🐍 For Advanced Learners — Python Code to Evaluate a Model (Practicals only — not assessed in theory paper)
If your teacher has assigned the Python evaluation practical, here is the standard approach using scikit-learn:
python
from sklearn.metrics import confusion_matrix, classification_report # y_test = actual labels, y_pred = model predictions cm = confusion_matrix(y_test, y_pred) print("Confusion Matrix:\n", cm) print(classification_report(y_test, y_pred))
classification_reportprints Precision, Recall, F1 Score, and Accuracy in one step. Save the output as a screenshot for your practical file.
The Four Evaluation Metrics (This is Where Marks Come From)
Now that you have your confusion matrix, you calculate 4 important metrics. Examiners will give you the matrix and ask you to calculate these.
Metric 1: Accuracy (Overall Correctness)
Question it answers: “Out of all predictions, how many were correct?”
Formula:
Accuracy = (TP + TN) / (TP + TN + FP + FN) × 100%
In our spam example:
Accuracy = (70 + 100) / (70 + 100 + 20 + 10) × 100%
= 170 / 200 × 100%
= 85%
What it means: The model got 85% predictions right.
When to use: When both classes (spam/not spam) are equally important.
⚠️ WARNING: Accuracy can be misleading! Read the next example carefully:
The Accuracy Trap (CBSE Loves This!)
Scenario: COVID-19 test on 1000 people
- 990 people are actually healthy
- 10 people actually have COVID
Bad Model: Always predicts “Healthy” for everyone
Confusion Matrix:
| PREDICTED: COVID | PREDICTED: Healthy | Total | |
|---|---|---|---|
| ACTUAL: COVID | 0 (TP) | 10 (FN) | 10 |
| ACTUAL: Healthy | 0 (FP) | 990 (TN) | 990 |
| Total | 0 | 1000 | 1000 |
Accuracy = (0 + 990) / 1000 = 99% 😱
BUT this model is USELESS! It missed all 10 COVID patients (they’ll spread the disease).
Lesson: When data is imbalanced (one class is much larger), accuracy is a bad metric. We need better metrics…
Metric 2: Precision (How Accurate are Positive Predictions?)
Question it answers: “When I predict POSITIVE, how often am I correct?”
Formula:
Precision = TP / (TP + FP) × 100%
Think of it as: Of all the “alarms” you raised, how many were real?
Spam Filter Example:
Precision = 70 / (70 + 20) × 100%
= 70 / 90 × 100%
= 77.78%
What it means: When the filter says “This is spam,” it’s correct 78% of the time.
When Precision matters most:
- Spam filtering: False Positives are bad (important emails in spam folder)
- Legal system: Don’t jail innocent people
- YouTube copyright strikes: Don’t flag original content
High Precision = Fewer False Alarms
Metric 3: Recall (How Many Positives Did We Catch?)
Question it answers: “Of all the ACTUAL positives, how many did I find?”
Formula:
Recall = TP / (TP + FN) × 100%Also called: Sensitivity, True Positive Rate (TPR)
Think of it as: How many needles did you find in the haystack?
Spam Filter Example:
Recall = 70 / (70 + 10) × 100%
= 70 / 80 × 100%
= 87.5%What it means: The filter caught 87.5% of all spam emails (but missed 12.5%).
When Recall matters most:
- Cancer diagnosis: Don’t miss a single cancer patient (False Negatives are deadly)
- Fraud detection: Catch as many frauds as possible
- Terrorist screening: Better to check extra people than miss one
High Recall = Fewer Missed Cases
The Precision vs Recall Tradeoff (EXAM FAVORITE!)
You can’t maximize both. Here’s why:
Scenario 1: Your spam filter is STRICT (High Precision)
- Flags only obvious spam → Fewer false alarms (FP ↓)
- But misses some spam → More missed spam (FN ↑)
- Precision ↑, Recall ↓
Scenario 2: Your spam filter is LOOSE (High Recall)
- Flags anything suspicious → Catches all spam (FN ↓)
- But flags legitimate emails too → More false alarms (FP ↑)
- Recall ↑, Precision ↓
Exam Question Pattern:
“You’re building a COVID detection model. Should you optimize for Precision or Recall? Justify.”
Answer:
“Recall, because missing a COVID patient (False Negative) is more dangerous than a False Positive. Better to test extra people than miss infected ones.”
Quick Comparison: Precision vs Recall vs F1 Score
| Precision | Recall | F1 Score | |
|---|---|---|---|
| Formula | TP ÷ (TP + FP) | TP ÷ (TP + FN) | 2 × (P × R) ÷ (P + R) |
| Question it answers | Of all my positive predictions, how many were right? | Of all actual positives, how many did I catch? | Am I balanced across both? |
| Use when… | False Positives are costly | False Negatives are dangerous | Both errors matter equally |
| India example | Aadhaar duplicate detection — don’t flag real citizens as duplicates | NITI Aayog TB screening — don’t miss a single TB case | UPI fraud detection — balance between blocking real fraud and not disrupting genuine payments |
| If this is low, it means… | Too many false alarms | Too many missed cases | Either P or R (or both) is low |
Metric 4: F1 Score (The Best of Both Worlds)
Question it answers: “What if I want BOTH precision and recall to be high?”
Formula:
F1 Score = 2 × (Precision × Recall) / (Precision + Recall)Why it’s special: It’s the harmonic mean (not arithmetic mean) of Precision and Recall.
Spam Filter Example:
Precision = 77.78%
Recall = 87.5%
F1 = 2 × (77.78 × 87.5) / (77.78 + 87.5)
= 2 × 6806.25 / 165.28
= 13612.5 / 165.28
= 82.35%What it means: Balanced measure of model performance.
When to use F1 Score:
- When both False Positives and False Negatives are bad
- When data is imbalanced
- When you need ONE number to compare models
Special Property:
- If either Precision or Recall is very low, F1 will be low
- F1 = 1 (perfect) only when both P and R = 1
Complete Worked Example (Board Exam Style)
Question: An AI model diagnoses heart disease in 500 patients. The confusion matrix is:
| PREDICTED: Disease | PREDICTED: Healthy | Total | |
|---|---|---|---|
| ACTUAL: Disease | 180 (TP) | 20 (FN) | 200 |
| ACTUAL: Healthy | 30 (FP) | 270 (TN) | 300 |
| Total | 210 | 290 | 500 |
Calculate:
- Accuracy
- Precision
- Recall
- F1 Score
- Which metric is most important for this problem? Why?
Solution:
Given:
- TP = 180 (correctly detected disease)
- TN = 270 (correctly detected healthy)
- FP = 30 (false alarm – told healthy person they’re sick)
- FN = 20 (missed disease – told sick person they’re healthy)
1. Accuracy:
Accuracy = (TP + TN) / Total
= (180 + 270) / 500
= 450 / 500
= 0.90 or 90%2. Precision:
Precision = TP / (TP + FP)
= 180 / (180 + 30)
= 180 / 210
= 0.857 or 85.7%What it means: When model says “Disease,” it’s correct 85.7% of the time.
3. Recall:
Recall = TP / (TP + FN)
= 180 / (180 + 20)
= 180 / 200
= 0.90 or 90%What it means: Model detected 90% of all actual disease cases (missed 10%).
4. F1 Score:
F1 = 2 × (Precision × Recall) / (Precision + Recall)
= 2 × (0.857 × 0.90) / (0.857 + 0.90)
= 2 × 0.7713 / 1.757
= 1.5426 / 1.757
= 0.878 or 87.8%5. Most Important Metric:
Answer: Recall is most important for heart disease diagnosis.
Reasoning:
- False Negative (missing a disease) can be fatal
- False Positive (false alarm) is less dangerous – just do more tests
- Better to have 30 false alarms than miss 20 heart patients
- In medical diagnosis, we prioritize not missing any sick person
Common Mistakes Students Make (Avoid These!)
Mistake 1: Confusing Rows and Columns
When solving confusion matrix class 10 problems, students often make these errors. Learn from them:
❌ Wrong: Putting Predicted on rows, Actual on columns ✅ Correct: ACTUAL on rows (Y-axis), PREDICTED on columns (X-axis)
Mistake 2: Mixing Up FP and FN
❌ Wrong: “False Positive means I predicted Negative but actual was Positive” ✅ Correct: “False Positive means I predicted POSITIVE but actual was NEGATIVE (false alarm)”
Memory Trick: The first word (False/True) describes PREDICTION.
- False Positive = Predicted Positive falsely
- True Positive = Predicted Positive truly
Mistake 3: Wrong Formula for Precision/Recall
❌ Wrong: Precision = TP / (TP + TN) ✅ Correct: Precision = TP / (TP + FP)
Remember: Precision looks at the PREDICTED POSITIVE column only.
Mistake 4: Forgetting ×100 for Percentage
- Formulas give decimal (e.g., 0.85)
- Board exams often expect percentage (85%)
- Always multiply by 100 or write “× 100%” in formula
Quick Reference Formulas (Screenshot This!)
| Term | One-Line Definition |
|---|---|
| Confusion Matrix | A 2×2 table organising predictions into TP, TN, FP, and FN |
| True Positive (TP) | Predicted Positive — actually Positive (correct positive prediction) |
| True Negative (TN) | Predicted Negative — actually Negative (correct negative prediction) |
| False Positive (FP) | Predicted Positive — actually Negative (false alarm; Type I Error) |
| False Negative (FN) | Predicted Negative — actually Positive (missed case; Type II Error) |
| Accuracy | (TP + TN) ÷ Total — overall correctness; misleading on imbalanced data |
| Precision | TP ÷ (TP + FP) — quality of positive predictions; use when FP is costly |
| Recall | TP ÷ (TP + FN) — coverage of actual positives; use when FN is dangerous |
| F1 Score | 2×(P×R)÷(P+R) — harmonic mean of Precision and Recall; use when balance matters |
| Imbalanced Data | Dataset where one class has far more samples than the other |
| Type I Error | False Positive — incorrectly rejecting a true negative |
| Type II Error | False Negative — incorrectly accepting a false negative |
Bonus Formulas (Sometimes Asked):
- Specificity (True Negative Rate): TN / (TN + FP)
- False Positive Rate: FP / (FP + TN)
Before your practical exam, confirm you can:
☑ Draw a blank confusion matrix and label all four cells correctly
☑ Fill a confusion matrix from a given scenario without prompting
☑ Calculate all four metrics with full working shown
☑ Explain which metric to use and justify your choice
☑ Name one ethical concern that affects model evaluation
☐ Answer all viva questions on this topic confidently under pressure
Practice Problems (Solve These Now!)
Let’s practice what you’ve learned about confusion matrix class 10 concepts with real exam-style problem
Problem 1: Email Spam Filter
Your spam filter tested 1000 emails:
- 400 were actually spam, 600 were ham
- Correctly caught 350 spam (TP)
- Wrongly flagged 50 ham as spam (FP)
Questions:
- Draw the confusion matrix
- Calculate Accuracy, Precision, Recall, F1
- Is this a good spam filter? Explain.
Confusion Matrix:
- TP = 350
- FP = 50
- FN = 400 – 350 = 50
- TN = 600 – 50 = 550
| PREDICTED: Spam | PREDICTED: Ham | Total | |
|---|---|---|---|
| ACTUAL: Spam | 350 (TP) | 50 (FN) | 400 |
| ACTUAL: Ham | 50 (FP) | 550 (TN) | 600 |
| Total | 400 | 600 | 1000 |
Calculations:
- Accuracy = (350 + 550) / 1000 = 90%
- Precision = 350 / (350 + 50) = 87.5%
- Recall = 350 / (350 + 50) = 87.5%
- F1 = 2 × (87.5 × 87.5) / (87.5 + 87.5) = 87.5%
Evaluation: Good filter! 90% accuracy, balanced precision and recall. Only 50 false alarms and missed 50 spam.</details>
Problem 2: COVID-19 Testing (Imbalanced Data)
Hospital tests 1000 people:
- 50 actually have COVID, 950 are healthy
- Correctly identified 45 COVID patients (TP)
- Wrongly told 20 healthy people they have COVID (FP)
Questions:
- Fill the confusion matrix
- Calculate all 4 metrics
- Why is accuracy misleading here?
Matrix:
- TP = 45
- FP = 20
- FN = 50 – 45 = 5
- TN = 950 – 20 = 930
Metrics:
- Accuracy = (45 + 930) / 1000 = 97.5%
- Precision = 45 / (45 + 20) = 69.2%
- Recall = 45 / (45 + 5) = 90%
- F1 = 2 × (69.2 × 90) / (69.2 + 90) = 78.3%
Why accuracy is misleading:
- 97.5% looks great!
- But precision is only 69% (lots of false alarms)
- More importantly, even a dumb model that always says “Healthy” would get 95% accuracy (because 95% are actually healthy)
- F1 Score (78.3%) gives a more realistic picture
How This Appears in Orange Data Mining (Practical Exam)
In your Class 10 AI practical exam, you’ll use Orange Data Mining tool. After training a model, you’ll see a confusion matrix like this:
Orange Output:
| Cat | Dog | Bird | |
|---|---|---|---|
| Cat | 85 ✅ | 3 ❌ | 2 ❌ |
| Dog | 5 ❌ | 92 ✅ | 3 ❌ |
| Bird | 2 ❌ | 4 ❌ | 94 ✅ |
This is a 3-class matrix (not binary), but same logic:
- Diagonal = Correct predictions (85 + 92 + 94)
- Off-diagonal = Mistakes
For multi-class, calculate metrics for each class:
- Cat Precision = 85 / (85 + 5 + 2) = 92.4%
- Cat Recall = 85 / (85 + 3 + 2) = 94.4%
Don’t panic in exam! Just identify TP, FP, FN for the class they ask about.
Exam Tips: How to Score Full Marks
For 2-Mark Questions:
✅ Write the formula first (1 mark) ✅ Show calculation with values (1 mark)
Example:
Q: Calculate Precision. TP=30, FP=5
Answer: Precision = TP / (TP + FP) = 30 / (30 + 5) = 30 / 35 = 0.857 or 85.7%
For 4-Mark Questions:
✅ Draw the confusion matrix (1 mark) ✅ Calculate 2 metrics (2 marks) ✅ Explain which metric is important and why (1 mark)
For Viva:
Favorite Questions:
- “What is the difference between Precision and Recall?”
- “When would you use F1 Score instead of Accuracy?”
- “Explain False Positive and False Negative with examples”
Pro Tip: Always give medical examples (easy to relate, examiners love them).
Practice Questions — Board Exam Format
2-Mark Question
Q1. An AI model for detecting defective products on a factory assembly line has the following results: TP = 45, FP = 5, FN = 15, TN = 135. Calculate the Recall of this model.
Model Answer:
Recall = TP ÷ (TP + FN) Recall = 45 ÷ (45 + 15) Recall = 45 ÷ 60 Recall = 0.75 or 75%
Examiner note: A complete 2-mark answer shows the formula (1 mark) and the substituted calculation with result (1 mark). Writing only the final answer without the formula typically scores 0–1 marks. Students who add “This means the model detected 75% of all actual defective products” demonstrate understanding and are more likely to score full marks in borderline cases.
4-Mark Question
Q2. A spam email classifier is tested on 500 emails. 200 are actual spam and 300 are legitimate. The model correctly identifies 160 spam emails and incorrectly flags 40 legitimate emails as spam.
(a) Draw and fill the complete confusion matrix. (b) Calculate Precision and Recall. (c) Which metric is more important for a spam filter used in a professional office — and why?
Model Answer:
(a) Confusion Matrix:
| Predicted: Spam | Predicted: Not Spam | Total | |
|---|---|---|---|
| Actual: Spam | 160 (TP) | 40 (FN) | 200 |
| Actual: Not Spam | 40 (FP) | 260 (TN) | 300 |
| Total | 200 | 300 | 500 |
Note: FN = 200 − 160 = 40; TN = 300 − 40 = 260
(b) Precision and Recall:
Precision = TP ÷ (TP + FP) = 160 ÷ (160 + 40) = 160 ÷ 200 = 0.80 or 80%
Recall = TP ÷ (TP + FN) = 160 ÷ (160 + 40) = 160 ÷ 200 = 0.80 or 80%
(c) More important metric:
Precision is more important for a professional office spam filter. In a professional setting, a False Positive (legitimate email marked as spam) causes direct business harm — a client email, a job offer, or an invoice could be missed. A False Negative (spam reaching the inbox) is an inconvenience but can be manually deleted. When the cost of false alarms exceeds the cost of missed cases, Precision is the priority metric.
Examiner note: Part (c) is where most students leave marks on the table. State the metric, explain what error type it minimises, and connect that to the specific scenario. A justification without scenario context scores 1/2 for part (c).
MCQ
Q3. A disease screening model reports 99% accuracy on a dataset where 99% of people are healthy and 1% have the disease. What does this tell you about the model?
(A) The model is excellent and can be deployed immediately (B) The model may be predicting “Healthy” for everyone and still achieving high accuracy (C) The model has high Recall and should be used in hospitals (D) Accuracy of 99% always means high Precision and Recall
Answer: (B)
Explanation: On heavily imbalanced datasets, a model that always predicts the majority class achieves accuracy equal to the majority class proportion — without learning anything useful. A model that predicts “Healthy” for all 1000 patients scores 99% accuracy but detects 0 disease cases (Recall = 0%). F1 Score or Recall should be used to evaluate models on imbalanced medical data.
Frequently Asked Questions
Q1. What is the difference between False Positive and False Negative — I keep mixing them up?
The first word (True or False) tells you whether the prediction was correct. The second word (Positive or Negative) tells you what the model predicted. So a False Positive means the model predicted Positive — but was wrong (it was actually Negative). A False Negative means the model predicted Negative — but was wrong (it was actually Positive). The most reliable memory trick: False Positive = false alarm; False Negative = missed case.
Q2. When should I use F1 Score instead of Accuracy?
Use F1 Score whenever your dataset is imbalanced (one class is much larger than the other) or whenever both types of errors — missing a case and raising a false alarm — carry real consequences. Accuracy rewards a model for being right on the common class. F1 Score requires it to be right on the rare class too. In CBSE exam answers, always state both the metric name and the reason in one sentence: “F1 Score is preferred here because the data is imbalanced and both Precision and Recall matter.”
Q3. The confusion matrix in Orange Data Mining shows three rows and three columns — how do I calculate Precision for one class?
For a multi-class matrix, calculate Precision for a single class by treating that class as “Positive” and everything else as “Negative.” Precision for Class A = (correctly predicted A) ÷ (total predictions of A) = diagonal value ÷ column sum for A. Your Orange output highlights the diagonal — those are all the correct predictions. Off-diagonal values in that column are the False Positives for Class A. Use the same logic as the binary case.
Q4. Can a model have high Precision and high Recall at the same time?
Yes — but it requires a well-trained model on balanced data. In practice there is often a tradeoff: making a model more conservative (predicting Positive only when very certain) increases Precision but reduces Recall, because it starts missing borderline true Positives. F1 Score captures this balance. A model with F1 Score above 0.85 is generally considered to have both metrics in a good range. Perfect Precision and Recall (both = 1.0) means zero False Positives and zero False Negatives — rare in real-world models.
Q5. Do professionals actually use confusion matrices in real AI jobs — or is this just for CBSE?
Confusion matrices are used daily by data scientists, ML engineers, and AI product managers. When I was working on a quality control system for a manufacturing plant, we reviewed the confusion matrix of our defect detection model every week — specifically the False Negative rate, because missing a defective part cost far more than a false alarm. In India, teams at NITI Aayog building AI-powered healthcare screening tools, and product teams at companies like Flipkart running fraud detection models, use precision-recall tradeoffs as standard decision frameworks. Understanding this concept now means you already think the way working AI professionals do.
Real-World Applications (For Understanding)
1. YouTube Copyright Detection
- High Precision needed: Don’t flag original content (False Positive ruins creators)
- Recall less important: Missing some pirated videos is acceptable
2. Cancer Screening
- High Recall needed: Don’t miss any cancer patient (False Negative is deadly)
- Precision less important: False alarms can be verified with more tests
3. Face Unlock on Phone
- Balance needed:
- Don’t unlock for wrong person (Precision)
- Don’t lock out the owner (Recall)
- That’s why F1 Score matters!
Ethical Concerns Around Model Evaluation
The CBSE Class 10 AI syllabus explicitly covers ethics in model evaluation. This is not a soft topic — it appears in board exams and viva questions. Three concerns you must know:
1. Bias in Evaluation Data
If your test dataset does not represent all groups equally, your evaluation metrics will be misleading even if mathematically correct.
India example: An AI model trained to detect loan defaulters on historical banking data from urban India will show high accuracy — but if it has never seen data from rural farmers or MSMEs, it is systematically biased. A 92% accuracy on the test set means nothing if that test set only contains urban customers.
Exam angle: If asked “what ethical concern could affect your confusion matrix results?” — bias in training or test data is the correct answer.
2. Transparency in Metric Selection
Choosing to report only Accuracy when Recall is the relevant metric is a form of misleading representation — even if you calculate Accuracy correctly.
Real-world consequence: A healthcare company that reports “our AI model is 98% accurate” for a rare disease detection tool may be hiding the fact that Recall is 40% — meaning it misses 60% of sick patients. High accuracy on imbalanced data conceals dangerous False Negatives.
Exam angle: You should always justify why you selected a particular metric — not just calculate it.
3. Accuracy Is Not Always Honest
An AI model that always predicts the majority class achieves high accuracy on imbalanced datasets — without actually learning anything. This is the “accuracy trap” you already saw in the COVID example above. Reporting accuracy as the sole metric in such cases is ethically problematic because it creates a false impression of model quality.
Key takeaway for exams: When data is imbalanced, accuracy is not a trustworthy metric. Use F1 Score or Recall depending on the cost of each error type.
Try It Yourself — CBSE Activities
Your Class 10 CBSE syllabus specifies three named activities for this unit. If your teacher has assigned any of these for your practical file, here is how to approach each one.
Activity 1: Build the Confusion Matrix from Scratch
What to do:
- Take any classification dataset — your teacher may provide one, or use the spam email example from this post (200 emails, TP=70, TN=100, FP=20, FN=10).
- Draw the 2×2 matrix on paper first: Actual on rows (Y-axis), Predicted on columns (X-axis).
- Fill in TP, TN, FP, FN from the given data.
- Label each cell with its full name (True Positive, False Negative, etc.) — not just the abbreviation.
- Verify: TP + FP + FN + TN = total observations.
What to document in your practical file: A neatly drawn or printed confusion matrix with all four cells labelled, the dataset description, and the verification calculation.
Activity 2: Calculate the Accuracy of the Classifier Model
What to do:
- Start with your completed confusion matrix from Activity 1.
- Apply the formula: Accuracy = (TP + TN) ÷ (TP + TN + FP + FN) × 100%
- Show all working — do not just write the final number.
- Write one sentence interpreting the result: “This means the model correctly classified X% of all observations.”
What to document: Full formula, substituted values, calculated result, and the one-sentence interpretation. Examiners award marks for interpretation, not just computation.
Activity 3: Decide the Appropriate Metric to Evaluate the AI Model
What to do:
- Your teacher will give you a scenario (or use one of the examples from this post — COVID testing, spam filter, cancer diagnosis).
- Identify: What type of error is more costly in this scenario? A False Positive or a False Negative?
- Select the appropriate metric based on that analysis:
- False Positives costly → Prioritise Precision
- False Negatives costly → Prioritise Recall
- Both errors costly → Use F1 Score
- Balanced data, both errors equal → Accuracy is acceptable
- Write a 2–3 sentence justification.
What to document: The scenario, your error cost analysis, your metric choice, and the justification. This is the activity most likely to appear as a viva question.
Your Action Plan for This Topic
Exam Practice Checklist
- ☐ I can draw a blank 2×2 confusion matrix and label all four cells from memory
- ☐ I can fill a confusion matrix from a word problem (identifying TP, FP, FN, TN from the scenario description)
- ☐ I can write all four metric formulas without referring to notes
- ☐ I have solved at least one full 4-mark problem showing complete working
- ☐ I can explain the “accuracy trap” using the COVID or cancer screening example
- ☐ I can justify metric selection (Precision vs Recall vs F1) for three different scenarios
- ☐ I have practised the three CBSE activities and documented them in my practical file
Interactive Tool
Orange Data Mining has a built-in Confusion Matrix widget. After training any classification model in Orange, connect it to the Confusion Matrix widget (found under Evaluate in the widget toolbar) to see your model’s TP, TN, FP, FN instantly. Try it with the Palmer Penguins dataset your teacher uses in class — evaluate the model and calculate Precision and Recall manually, then compare with Orange’s output.
Download Orange Data Mining free → orangedatamining.com
Project Idea: Build Your Own Spam Classifier and Evaluate It
A focused, achievable project you can complete in one weekend:
Step 1 — Get the data. Download the SMS Spam Collection dataset from Kaggle (free, 5,574 messages, labelled spam/ham). This is a real-world Indian-friendly dataset used in published research.
Step 2 — Train and evaluate in Orange. Load the CSV in Orange, use the Naive Bayes or kNN classifier, and connect a Confusion Matrix widget. Record your TP, FP, FN, TN values.
Step 3 — Write your analysis. Calculate Accuracy, Precision, Recall, and F1 Score. Write 3–4 sentences explaining which metric matters most for a spam filter and why, using the values you calculated. This becomes your project documentation.
This project directly maps to CBSE Class 10 Unit 3 and Unit 4 — and can be included in your practical file.
Summary: The 5 Things You MUST Remember
- Confusion Matrix = 4 boxes: TP, TN, FP, FN
- Diagonal = Correct, Off-diagonal = Mistakes
- Accuracy = Overall correctness (misleading with imbalanced data)
- Precision = Of my positive predictions, how many were correct?
- Use when False Positives are costly
- Recall = Of all actual positives, how many did I catch?
- Use when False Negatives are dangerous
- F1 Score = Harmonic mean of Precision and Recall
- Use when you want balance
You’ve now mastered the confusion matrix for Class 10 CBSE AI! With these concepts clear, you’re ready to tackle any evaluation question in your board exams.
If this helped you, share it with your classmates – let’s make AI easier for everyone.
