Your CBSE Class 10 AI syllabus asks you to “understand, create and implement the concept of Decision Trees.” That means you need more than a definition — you need to be able to draw one, label its parts correctly, and explain how it works with an example. This guide covers all of that clearly, so you are ready for any question this topic throws at you.
What You Will Learn
- What a decision tree is and how it makes predictions
- The four key parts of a decision tree — with correct terminology
- How to draw a decision tree for any scenario, step by step
- Real-world examples from India and how to connect them to exam answers
What Is a Decision Tree?
A decision tree is a supervised machine learning algorithm that makes predictions by asking a series of yes/no questions, branching at each step, until it reaches a final answer.
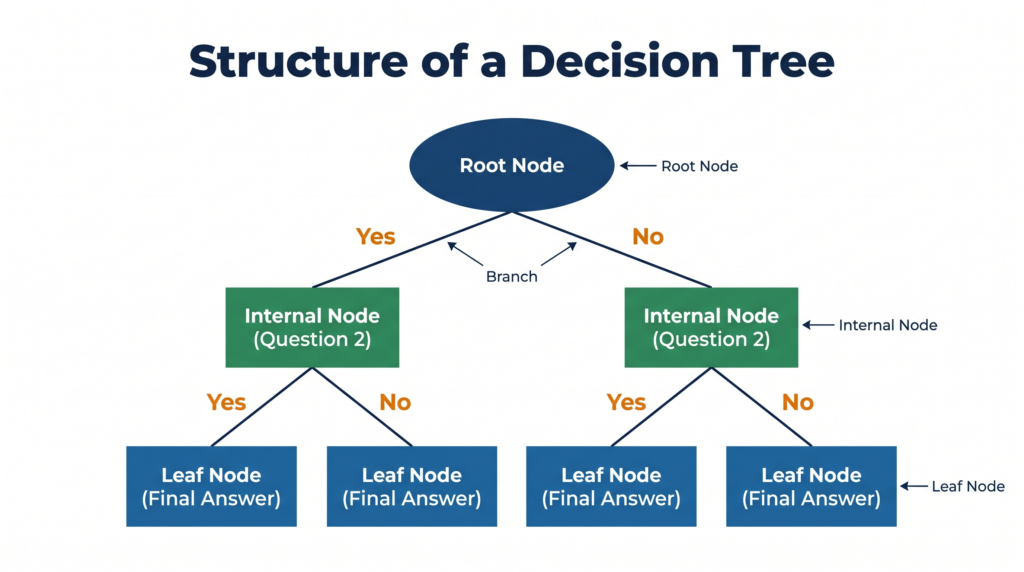
It is called a “tree” because its structure looks like an upside-down tree — one root at the top, branches spreading downward, and leaves at the bottom. Every question you answer takes you one branch closer to the final prediction.
Decision trees are used for classification — they predict which category an input belongs to. They are one of the most visual and intuitive machine learning algorithms, making them ideal for explaining how AI makes decisions.
📌 Class 10 CBSE Note: The 2025-26 syllabus (page 2, learning outcome #14) explicitly states: “Understand, create and implement the concept of Decision Trees.” This means drawing, labelling, and explaining a tree are all fair game in your exam — not just defining it.
The Four Parts of a Decision Tree — Know These for Your Exam
Every decision tree has exactly four types of components. You must be able to identify and label each one.
1. Root Node
The root node is the topmost node of the tree — the starting question. It represents the most important feature — the one that divides the data most usefully. Every prediction starts here.
Think of it as the first question a doctor asks when you walk in: “Do you have a fever?” Everything branches from this first question.
2. Internal Node (Decision Node)
An internal node is any question node that is not the root and not the final answer. It represents a further condition that needs to be checked before reaching a conclusion. A tree can have many internal nodes depending on complexity.
3. Branch
A branch is the arrow connecting one node to the next. Each branch represents the outcome of a question — typically “Yes” or “No.” Following a branch means you have answered that question and are moving deeper into the tree.
4. Leaf Node (Terminal Node)
A leaf node is the final node at the bottom of any branch — it represents the prediction or decision. Once you reach a leaf node, the tree has made its classification. There are no more questions to ask.
Memory shortcut: Root → Branches → Leaves — just like a real tree, but upside down.
How a Decision Tree Makes a Prediction — Step by Step
- Start at the root node — answer the first question (Yes or No)
- Follow the branch that matches your answer
- Arrive at the next node — answer its question
- Keep following branches until you reach a leaf node
- The leaf node is your prediction — the tree’s classification for that input
The path from root to leaf that you followed is called a decision path or rule. Every leaf node in the tree represents one complete rule the algorithm has learned from the training data.
Drawing a Decision Tree — A Worked Example
Let us build a decision tree for one everyday scenario: “Should I carry an umbrella today?”
Features (questions) available:
- Is it cloudy? (Yes/No)
- Is the humidity above 70%? (Yes/No)
Step 1 — Choose the root node. “Is it cloudy?” is the most important first question — if it is not cloudy, no umbrella is needed regardless of humidity.
Step 2 — Branch from the root:
- Yes (it is cloudy) → ask the next question
- No (it is not cloudy) → Leaf node: “Don’t carry umbrella”
Step 3 — Add the internal node for the “Yes” branch:
- “Is humidity > 70%?”
- Yes → Leaf node: “Carry umbrella ☂️”
- No → Leaf node: “Maybe carry umbrella”
Is it cloudy?
├── No → [Leaf] Don't carry umbrella ☀️
└── Yes → Is humidity > 70%?
├── Yes → [Leaf] Carry umbrella ☂️
└── No → [Leaf] Maybe carry umbrella 🤔This is a complete, valid decision tree. Root node → two branches → one internal node → three leaf nodes. In your exam, you can draw any scenario in this format and label all four parts.

A Second Example — Loan Approval at a Bank
This is one of the most commonly cited real-world decision tree applications and works well in exam answers.
Scenario: SBI uses a decision tree to decide whether to approve a personal loan.
Is monthly income > ₹30,000?
├── No → [Leaf] Loan Rejected ❌
└── Yes → Is credit score > 700?
├── No → [Leaf] Loan Rejected ❌
└── Yes → Is existing debt < 40% of income?
├── Yes → [Leaf] Loan Approved ✅
└── No → [Leaf] Loan Rejected ❌What this shows: The tree asks the most important question first (income — if too low, no need to check further), then narrows down using credit score and debt ratio. Each leaf is a final classification: approved or rejected. The bank’s lending rules are encoded as decision paths.

Why Decision Trees Are Used in Practice
Decision trees have three properties that make them valuable beyond just CBSE:
1. Explainability: You can trace exactly why a prediction was made by following the decision path. This matters enormously in healthcare and banking, where regulators require explanations for AI decisions. “The loan was rejected because income < ₹30,000” — clear and auditable.
2. No data scaling needed: Unlike KNN or linear regression, decision trees do not require you to normalise or scale your input data. They handle raw values directly.
3. Handles both classification and regression: While your Class 10 syllabus focuses on classification trees, decision trees can also be used for regression tasks (predicting numbers). The CBSE scope is classification only — knowing this boundary protects you from going off-track in answers.
Key Terminology Quick Reference
| Term | Definition |
|---|---|
| Root Node | The topmost node — the first and most important question |
| Internal Node | Any middle question node — not the root, not a leaf |
| Branch | The connection between nodes representing a Yes/No answer |
| Leaf Node | The terminal node — contains the final prediction/classification |
| Decision Path | The route from root to a specific leaf node |
| Classification Tree | A decision tree whose leaf nodes are categories (not numbers) |
Quick Revision Box
| Term | One-Line Definition |
|---|---|
| Decision Tree | A supervised ML algorithm that makes predictions through a series of yes/no questions |
| Root Node | The topmost starting node — represents the most important feature |
| Internal Node | A middle node in the tree — asks a further question before reaching the answer |
| Branch | An arrow connecting nodes — represents the answer (Yes/No) to a question |
| Leaf Node | The bottom terminal node — contains the final prediction or classification |
| Decision Path | The complete route from root node to a leaf node — represents one learned rule |
Practice Questions
Question 1 (2 marks): What is a decision tree in machine learning? Name its four main components.
Model Answer: A decision tree is a supervised machine learning algorithm that makes classifications by asking a series of yes/no questions, branching at each step until a final prediction is reached. Its structure resembles an upside-down tree.
The four main components are:
- Root Node — the topmost starting question (most important feature)
- Internal Node — intermediate question nodes
- Branch — connections between nodes (Yes/No paths)
- Leaf Node — terminal nodes containing the final prediction
Question 2 (MCQ): In a decision tree used to predict whether a student will pass or fail, the final nodes that contain the predictions “Pass” and “Fail” are called:
(a) Root nodes — because they contain the most important decisions (b) Branch nodes — because they connect to multiple outcomes (c) Leaf nodes — because they are terminal nodes with the final prediction (d) Internal nodes — because they come after the root node
Answer: (c) Leaf nodes — because they are terminal nodes with the final prediction
Explanation: Leaf nodes (also called terminal nodes) are the end-points of a decision tree. They contain the final classification — in this case “Pass” or “Fail.” No further branching occurs after a leaf node. Root nodes are at the top, branches are the connecting arrows, and internal nodes ask intermediate questions.
Frequently Asked Questions
Q1. How does the tree know which question to ask first — why is the root node chosen the way it is?
The root node is the feature that best separates the data into meaningful groups — the one that reduces uncertainty the most. This is measured using concepts called information gain or Gini impurity. In simple terms: if one question immediately splits the data cleanly (e.g., “Is income below ₹20,000?” sorts out 60% of all loan rejections instantly), that question becomes the root. For your Class 10 exam, you do not need to calculate information gain — but knowing that the root is chosen for being the most informative feature is worth mentioning in a 4-mark answer.
Q2. Can a decision tree make wrong predictions?
Yes — all machine learning models, including decision trees, can make errors. A tree trained on limited or biased data may ask the wrong questions or miss important patterns. Decision trees are also prone to overfitting — where the tree grows so deep and complex that it memorises training data instead of learning general rules. In practice, this is managed by limiting tree depth (called “pruning”) or using multiple trees together (called a Random Forest). For your Class 10 exam, understanding that decision trees are not perfect and can overfit is a good extra point to include in answers where relevant.
Q3. Is a flowchart the same as a decision tree?
They look similar and are easy to confuse, but they serve different purposes. A flowchart is a diagram drawn by a human to describe a process or algorithm — it represents logic that was manually designed. A decision tree in machine learning is a model that was learned from data — the questions and thresholds were not hand-coded but discovered by an algorithm trained on thousands of examples. The visual structure is similar, but the origin is completely different: one is human-made, the other is data-driven.