Every time you type a message and WhatsApp autocompletes your sentence, or Google Translate converts your Hindi paragraph into English in under a second, you are already using natural language processing in CBSE AI — the exact topic that appears in your Class 10 and Class 11 exam, and connects directly to your Class 12 practical file.
This guide covers everything: what NLP is, why human language is hard for machines, all four phases, chatbot types, text processing concepts, real-world applications, and the CBSE activities you need to document in your practical file.
What You’ll Learn
- Why human language is so complex that machines need special techniques to understand it
- The four named phases of NLP — exactly as CBSE expects you to explain them
- Applications of NLP in everyday Indian life
- The difference between script bots and smart bots (a favourite exam question)
- Text normalisation, Bag of Words, and TF-IDF — with simple explanations
- How to complete the CBSE-specified NLP activities for your practical file
Why Human Language Is So Complex
Before a machine can understand text, it has to deal with something humans manage effortlessly: language is deeply ambiguous.
Consider this sentence: “The bank was steep.” Are we talking about a river bank or a financial bank? A human reader uses surrounding context to decide instantly. A machine has no such intuition — it must be given a systematic way to figure this out.
Human language is complex for several specific reasons that CBSE identifies as the starting point of NLP:
Ambiguity — the same word can mean different things. “Bat” can be an animal or a cricket bat. “Can you pass the salt?” is a question about ability, but it really means a request.
Variability — people say the same thing in many different ways. “The exam was cancelled”, “They called off the exam”, and “No exam today” all mean the same thing. A machine must understand all three.
Context dependence — the meaning of a word changes based on what surrounds it. “Cool” means cold in one sentence and impressive in another.
Informal language — people write “gonna”, “u r”, “LOL”, and “Hinglish” (Hindi + English mixed). Standard grammar rules break down completely here.
Sarcasm and tone — “Oh great, another power cut” is a complaint, not genuine happiness. Machines find this extremely difficult to detect.
This is why NLP is its own specialised field within AI — and why it requires a structured, step-by-step approach to work.
📘 Class 10 Callout Your CBSE Class 10 Unit 6 begins with exactly this topic: “Comprehend the complexities of natural languages and elaborate on the need for NLP techniques.” If an exam question asks “Why do machines find it difficult to understand human language?”, list any three of the above reasons with one-line explanations each.
📗 Class 11 Callout Class 11 Unit 7 labels this section “Understanding Human Language Complexity” and treats it as the foundation for all NLP work. In your IBM Project Debater article (a required practical activity), you will see how IBM’s AI dealt with precisely these challenges at a debate-level scale.
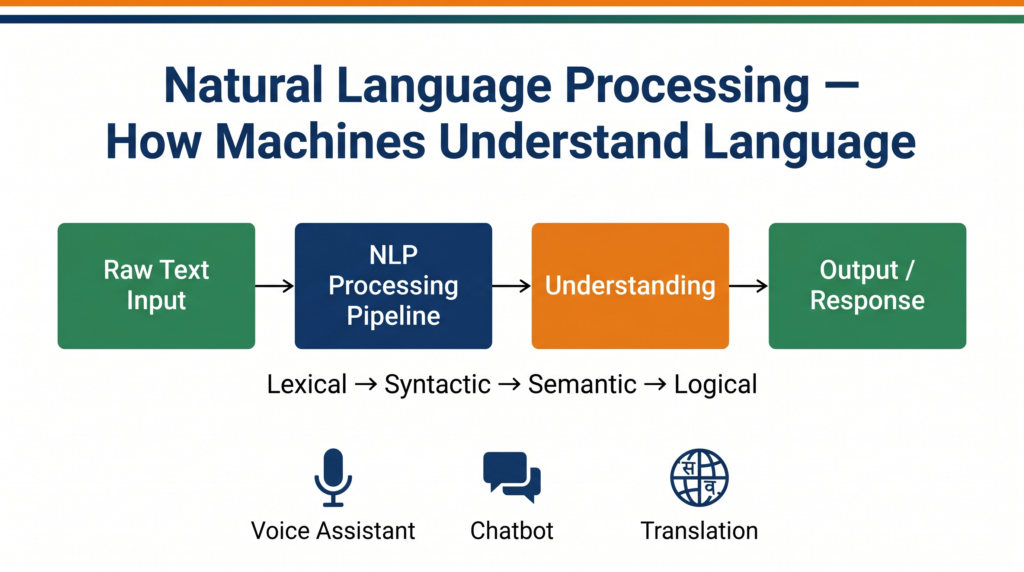
What Is Natural Language Processing?
Natural Language Processing (NLP) is the branch of AI that enables computers to read, understand, interpret, and generate human language in a way that is meaningful.
The key word is natural — as opposed to programming languages like Python or Java, which are designed to be unambiguous and precise. Natural languages grew organically over thousands of years and are full of exceptions, idioms, dialects, and cultural references.
NLP sits at the intersection of three fields: linguistics (the study of language), computer science (algorithms and data structures), and AI (learning from data). A good NLP system doesn’t just search for keywords — it understands meaning.
Applications of NLP
NLP is not a future technology. It is running around you right now.
Voice Assistants — when you say “Hey Google, set an alarm for 6 AM”, the system converts your speech to text and then uses NLP to understand the intent (“set alarm”) and the time parameter (“6 AM”). Google Assistant, Siri, and Alexa all run on NLP.
Auto-Generated Captions — YouTube’s automatic captions are generated using NLP combined with speech recognition. When you watch a lecture video and see live subtitles appearing, NLP is doing that work in real time.
Language Translation — Google Translate handles over 100 languages. When it translates a Hindi sentence like “मुझे भूख लगी है” to “I am hungry”, it is not doing word-for-word substitution — it is understanding grammatical structure and reconstructing meaning in the target language. India’s Bhashini project (by the Ministry of Electronics and IT) uses similar NLP technology to enable translation between all major Indian languages.
Sentiment Analysis — Zomato, Swiggy, and Amazon India analyse thousands of customer reviews every day to understand whether feedback is positive, negative, or neutral. This is sentiment analysis — a core NLP application that also appears in your CBSE practical.
Text Classification — spam filters in Gmail use NLP to read the content of emails and decide if they are spam before they reach your inbox.
Keyword Extraction — news aggregators like Inshorts automatically pull the key topics from long articles. The CBSE Class 10 curriculum includes a hands-on keyword extraction activity using Google Cloud’s Natural Language API.
Chatbots — customer service chatbots on IRCTC, bank websites, and telecom apps (like Airtel’s Airtel Thanks) use NLP to answer user queries without a human agent.
📘 Class 10 Callout Your syllabus explicitly lists these applications: voice assistants, auto-generated captions, language translation, sentiment analysis, text classification, and keyword extraction. In a 4-mark exam question asking for NLP applications, list four of these with one Indian real-world example each.
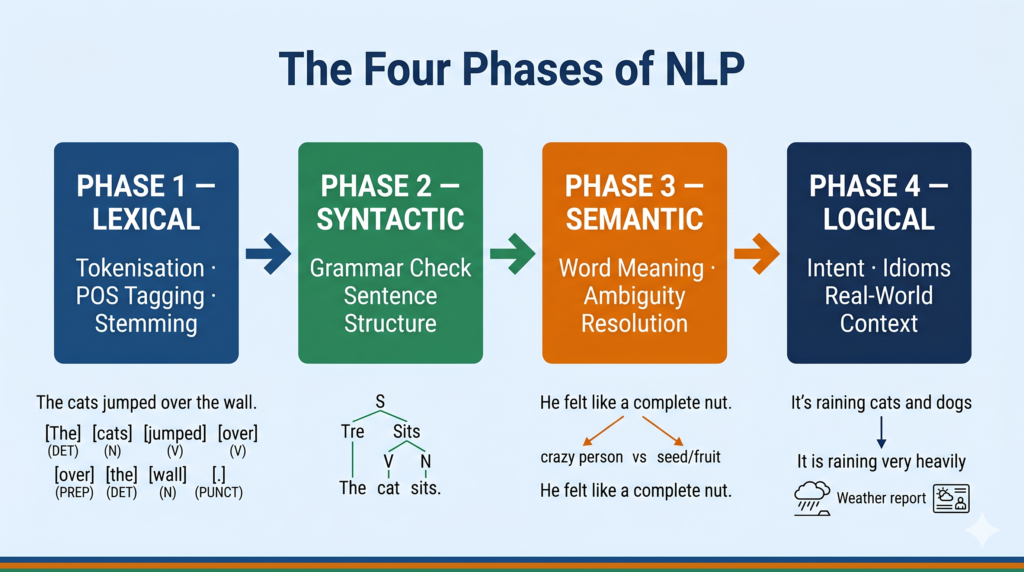
The Four Phases of NLP
This is the most important theory section for your exam. CBSE expects you to know and name all four phases in sequence.
When a machine receives a sentence as input, it does not process the whole sentence at once. It moves through four structured phases, each building on the last.
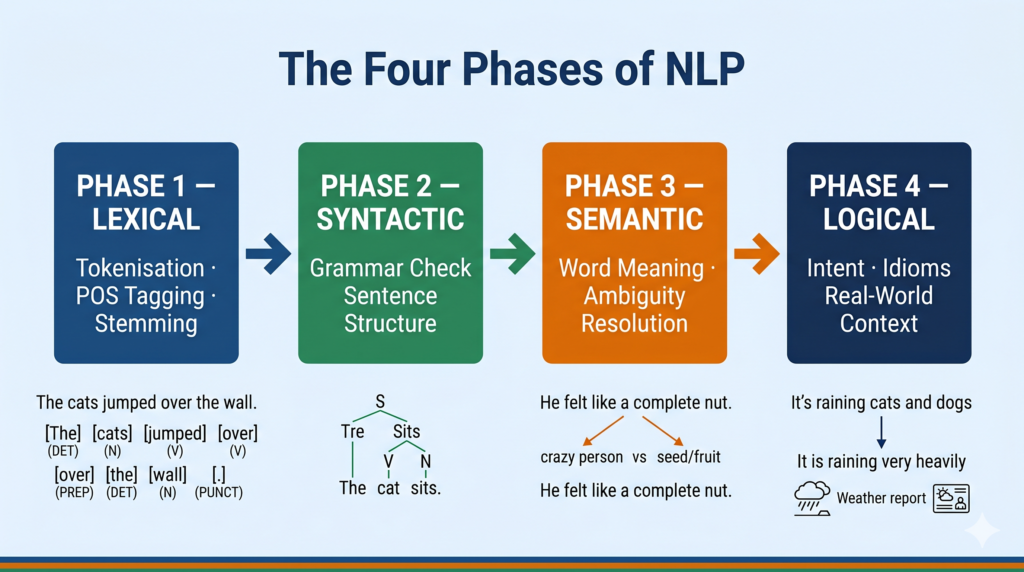
Phase 1 — Lexical Analysis
What it does: Breaks the text into its smallest units — words and punctuation — and understands their basic dictionary meaning.
The word lexicon means dictionary or vocabulary. In the lexical phase, the system takes a raw sentence and tokenises it — splits it into individual tokens (words). It also identifies whether each word is a noun, verb, adjective, and so on.
Example: Input sentence → “She sells seashells.” After lexical analysis → [“She”, “sells”, “seashells”] + Part-of-speech tags: [Pronoun, Verb, Noun]
Lexical analysis also removes stop words (common words like “the”, “is”, “a” that carry little meaning) and performs stemming or lemmatisation (reducing “running” → “run”, “better” → “good”).
Phase 2 — Syntactic Analysis
What it does: Checks whether the sentence follows proper grammatical rules and understands the relationships between words.
The word syntax means the arrangement of words to form sentences. In this phase, the system parses the sentence structure. It identifies the subject, verb, and object. It also catches grammatically incorrect sentences.
Example: “She sells seashells.” → Subject: She | Verb: sells | Object: seashells ✅ (grammatically correct) “Sells she seashells.” → ❌ Syntactic analysis flags this as incorrect English structure.
Think of syntactic analysis as the grammar-checker that runs before meaning is assigned.
Phase 3 — Semantic Analysis
What it does: Interprets the actual meaning of the sentence — not just its structure, but what it is communicating.
The word semantics means meaning. In this phase, the system resolves ambiguity and maps words to real-world concepts.
Example: “I went to the bank.” — Syntactically this is fine. Semantically, the system uses surrounding context to determine: is this a river bank or a financial bank?
Semantic analysis also handles synonyms (“happy” and “joyful” mean the same thing) and antonyms, and it links pronouns to the right nouns (“She sells seashells. She is an expert.” — Who is the expert? She = the seller).
Phase 4 — Logical Analysis (Pragmatic Analysis)
What it does: Understands the real-world intent and purpose behind the statement — what the speaker actually means beyond the literal words.
The word logical or pragmatic refers to real-world reasoning. In this phase, the system interprets intent.
Example: “Can you pass the salt?” — Logically, this is not a question about the listener’s ability. It is a request. The system must understand the implied intent.
Another example: “It’s raining cats and dogs.” — Semantically absurd if taken literally. Logically, this is an idiom meaning heavy rain.
| Phase | Key Question | What It Does |
|---|---|---|
| Lexical | What are the words? | Tokenisation, POS tagging, stemming |
| Syntactic | Are the words arranged correctly? | Grammar parsing, sentence structure |
| Semantic | What do the words mean? | Meaning, disambiguation, pronoun resolution |
| Logical | What does the speaker actually intend? | Intent, idioms, real-world context |
📗 Class 11 Callout The Class 11 Unit 7 syllabus lists “Phases of NLP” as a core theory topic. In your practical, you may be asked to write a POS (Part-of-Speech) tagging program — this is the output of the Lexical phase. That program is marked For Advanced Learners and will not appear in theory or practical exams, but it is excellent for your practical file and IBM SkillsBuild portfolio.
Chatbots — Script Bots vs Smart Bots
A chatbot is a computer program that simulates conversation with human users. Chatbots are one of the most visible real-world applications of NLP. CBSE Class 10 and Class 11 both cover chatbots, and the distinction between two types is a common exam question.
Script Bot (Rule-Based Bot)
A script bot works by matching user input to pre-written rules. The developer writes a list of patterns (like “if the user says X, reply with Y”). The bot has no ability to learn or handle inputs it has not been programmed for.
Characteristics:
- Follows a fixed script or decision tree
- Cannot handle unexpected questions
- Fast and predictable
- No AI learning involved
- Easy to build for narrow use cases
Example: An automated IVR (Interactive Voice Response) menu — “Press 1 for balance enquiry, press 2 for mini statement.” This is entirely scripted.
CBSE activity reference: Elizabot (https://www.masswerk.at/elizabot/) is a classic script bot from the 1960s. Try talking to it about an off-script topic and it will loop or give irrelevant responses.
Smart Bot (AI-Powered Bot)
A smart bot uses NLP and machine learning to understand the meaning behind a user’s query — not just match keywords. It can handle varied phrasing, learn from new data, and improve over time.
Characteristics:
- Understands intent, not just keywords
- Handles variations in phrasing
- Can be trained on new data
- Built on NLP models
- More complex to build, more powerful in use
Example: Google’s customer support chatbot, Airtel Thanks in-app assistant, and Mitsuku (https://www.kuki.ai/) — all understand diverse inputs and respond contextually.
| Feature | Script Bot | Smart Bot |
|---|---|---|
| Basis | Pre-written rules | NLP + Machine Learning |
| Flexibility | Low — fixed responses only | High — handles new inputs |
| Learning ability | None | Yes — improves with data |
| Complexity to build | Low | High |
| Example | IVR phone menu | Google Assistant |
| CBSE activity | Elizabot | Mitsuku / Cleverbot |
📘 Class 10 Callout This comparison table is exactly what CBSE expects for the “Script Bot vs Smart Bot” sub-unit. A 4-mark question could ask: “Distinguish between script bots and smart bots with examples.” Learn the table above — four points of distinction with examples is a complete answer.
📗 Class 11 Callout Class 11 practicals include building a chatbot using Dialogflow, Botsify, or Botpress — these are all smart bot platforms. When you build on Dialogflow, you are training intents and entities — which is NLP in action.
Text Processing Concepts
After understanding phases and chatbots, CBSE Class 10 introduces three text processing concepts. These are also the foundation of any NLP project.
Text Normalisation
Before any NLP analysis, raw text must be cleaned and standardised. This is called text normalisation. It includes several steps:
Tokenisation — splitting text into individual words or sentences. “I love AI.” → [“I”, “love”, “AI”]
Lowercasing — converting all text to lowercase so “AI”, “Ai”, and “ai” are treated the same.
Removing stop words — removing common words like “the”, “is”, “and”, “a” that add no analytical value.
Stemming — cutting words to their root form. “running”, “runner”, “runs” → “run”
Lemmatisation — a smarter version of stemming that uses vocabulary rules. “better” → “good” (stemming cannot do this)
Removing punctuation and special characters — so “Hello!” becomes “Hello”.
Text normalisation is always the first step in any NLP pipeline. Without it, the same word in different forms would be counted as different words, making analysis inaccurate.
Bag of Words (BoW)
Once text is normalised, we need to convert it into a format that machine learning algorithms can process — numbers. The Bag of Words model is the simplest and most widely used approach.
How it works:
- Take all the unique words across all documents in your dataset — this is your vocabulary.
- For each document, count how many times each vocabulary word appears.
- Represent each document as a vector of these counts.
Example:
Document 1: “AI is great. AI is the future.”
Document 2: “NLP is a part of AI.”
Vocabulary: [AI, is, great, the, future, NLP, a, part, of]
| Document | AI | is | great | the | future | NLP | a | part | of |
|---|---|---|---|---|---|---|---|---|---|
| Doc 1 | 2 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| Doc 2 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
Reading Doc 2 the same way: “NLP is a part of AI.” — AI appears once, is appears once, NLP appears once, a appears once, part appears once, of appears once, and great/the/future do not appear at all → vector: [1, 1, 0, 0, 0, 1, 1, 1, 1].
The bag of words representation ignores word order and grammar — it only counts occurrences. This is why it’s called a “bag” — the words are thrown in without sequence.
Limitation: BoW gives equal weight to all words, even if “AI” appears 100 times across all documents and “great” appears only once. Frequent words dominate the analysis.
TF-IDF (Term Frequency — Inverse Document Frequency)
TF-IDF solves the Bag of Words problem by giving higher weight to words that are rare across the dataset but frequent in a specific document — because those words are more likely to be meaningful to that document.
TF (Term Frequency) = how often a word appears in a document ÷ total words in that document
IDF (Inverse Document Frequency) = log(total documents ÷ number of documents containing the word)
TF-IDF Score = TF × IDF
A word that appears in every document (like “the”) gets a very low IDF score — it is not distinctive. A word that appears frequently in one document but rarely in others gets a high TF-IDF score — it is distinctive for that document.
TF-IDF is the engine behind most search engines, document classification systems, and recommendation systems.
📘 Class 10 Callout Your CBSE hands-on session covers Text Processing (normalisation + Bag of Words + TF-IDF). Be ready to explain: (1) what normalisation is and name three steps, (2) how BoW represents text, and (3) what problem TF-IDF solves that BoW cannot. These three points map directly to exam questions.
Real-World NLP Applications in India
Bhashini (MeitY) — India’s national language translation platform, built to make digital services accessible in all 22 scheduled languages. It uses NLP to translate, transcribe, and synthesise speech across languages including Hindi, Tamil, Telugu, Bengali, Marathi, and more. Built for a billion users who are not comfortable in English.
IRCTC Chatbot (Ask Disha) — the IRCTC railway booking portal uses a smart NLP chatbot called Ask Disha to help users check train schedules, PNR status, and fare enquiries. It handles thousands of queries per day without a human agent.
Zomato Review Analysis — Zomato processes lakhs of customer reviews using sentiment analysis to identify which restaurants are improving, which are declining, and what specific issues (food quality, delivery time, packaging) are being raised most frequently.
Aadhaar Grievance System — UIDAI uses text classification NLP to automatically route citizen grievance letters and complaints to the correct department based on the content of the message.
Common Mistakes Students Make in Exams
Mistake 1: Confusing “phases” with “applications” The four phases (Lexical, Syntactic, Semantic, Logical) describe how NLP works internally. Applications (voice assistants, translation, sentiment analysis) describe what NLP is used for. These are two different things. Answer each type of question using the correct category.
Correct version: If asked “What are the phases of NLP?”, answer: Lexical → Syntactic → Semantic → Logical. If asked “What are NLP applications?”, answer: translation, sentiment analysis, chatbots, etc.
Mistake 2: Saying script bots “use NLP” Script bots do not use NLP. They use pattern matching on pre-written rules. Only smart bots use NLP and machine learning. This is a key distinction CBSE tests.
Correct version: Script bots are rule-based. Smart bots use NLP and ML to understand intent.
Mistake 3: Describing Bag of Words as a full NLP model BoW is a text representation technique, not a complete NLP model. It converts text to numbers so that ML algorithms can be applied. Do not say “the Bag of Words model classifies sentiment” — it represents text; a separate classifier does the classification.
Correct version: “Bag of Words converts text into numerical vectors, which are then fed into a machine learning classifier.”
Mistake 4: Confusing Stemming and Lemmatisation Stemming is a rough, rule-based word-cutting process. Lemmatisation uses vocabulary knowledge to find the actual root word. “Better” → stemming gives “better” (no change), lemmatisation gives “good”.
Correct version: “Lemmatisation is more accurate than stemming as it uses linguistic rules to find the correct root word.”
Exam Strategy
For 2-mark questions: Define the term + give one example. For NLP: “NLP is the branch of AI that enables computers to understand, interpret, and generate human language. Example: Google Translate converting Hindi to English.”
For phases: name the phase + one-line function. “Lexical analysis breaks text into individual tokens and identifies parts of speech.”
For 4-mark questions: Use the comparison table format for Script Bot vs Smart Bot (4 differences = 4 marks). For applications, give 4 NLP applications with one India-relevant example each. For phases, name all four in order with one-line explanations.
Marks pattern (Class 10 CBSE): Unit 6 (NLP) is assessed in both Theory and Practicals. Theory covers: complexities of language, applications, stages, chatbot types, and text processing. Practical covers: sentiment analysis walkthrough using Orange Data Mining tool with a real dataset.
Class 11 NLP assessment: Unit 7 (Leveraging Linguistics and Computer Science) is in theory. Practicals include: IBM Project Debater article write-up, building a chatbot on Dialogflow/Botsify/Botpress, POS tagging program (Advanced Learners only — not evaluated in exams).
Try It Yourself — CBSE Activity
CBSE specifies three NLP activities for Class 10 and Class 11. Complete all of them and document with screenshots in your Practical File.
Activity 1 — Keyword Extraction (Class 10)
Tool: Google Cloud Natural Language API Link: https://cloud.google.com/natural-language
Steps:
- Open the link and click “Try the API”.
- Paste a paragraph of text — try a news article about a current topic in India.
- Click “Analyze” and select the “Entities” tab.
- Observe which keywords (entities) the API automatically extracts and how it categorises them (Person, Location, Organisation, Event, etc.).
- Try with a second paragraph and compare the entities extracted.
What to observe: Which words are identified as key entities? Does the system identify proper nouns (names, cities) differently from common nouns?
For your Practical File: Take screenshots of the input text and the extracted entities table. Write 2–3 sentences explaining what keyword extraction is and where it is used in real life.
Activity 2 — Play With Chatbots (Class 10)
Tools: Elizabot (https://www.masswerk.at/elizabot/), Mitsuku (https://www.kuki.ai/), Cleverbot (https://www.cleverbot.com/)
Steps:
- Open Elizabot and have a five-message conversation. Note how it responds.
- Ask it something completely off-script (e.g., “What is photosynthesis?”). Note the response.
- Open Mitsuku and ask the same questions. Compare the quality of responses.
- Note: which bot seems to understand context? Which one just pattern-matches?
What to document: Create a small comparison table in your file: Question asked | Elizabot response | Mitsuku response | Which felt more natural and why.
Activity 3 — IBM Project Debater Article (Class 11)
Task: Write a short article (300–400 words) titled “IBM Project Debater — Interesting Facts.”
What to cover: What is IBM Project Debater? What NLP challenges did it solve (understanding arguments, generating counter-arguments, detecting rhetoric)? What does it demonstrate about the state of AI language understanding?
Where to start: Search “IBM Project Debater” on IBM’s website or YouTube. The 2019 debate between Project Debater and champion debater Harish Natarajan is publicly available.
For your Practical File: This article is a mandatory Class 11 practical file submission.
Quick Revision Box
| Term | One-Line Definition |
|---|---|
| NLP | AI branch that enables machines to understand and generate human language |
| Tokenisation | Splitting text into individual words or sentences |
| Stop Words | Common words (the, is, a) removed before NLP analysis |
| Stemming | Cutting words to their approximate root (running → run) |
| Lemmatisation | Finding the correct root word using vocabulary rules (better → good) |
| Bag of Words | Representing text as word frequency counts in a vector |
| TF-IDF | Weighting words by how distinctive they are to a specific document |
| Script Bot | Rule-based chatbot that follows pre-written patterns |
| Smart Bot | AI-powered chatbot that uses NLP to understand user intent |
| Lexical Analysis | Phase 1 — tokenisation and basic word identification |
| Syntactic Analysis | Phase 2 — grammar checking and sentence structure |
| Semantic Analysis | Phase 3 — interpreting word meanings and resolving ambiguity |
| Logical Analysis | Phase 4 — understanding real-world intent and implied meaning |
| Sentiment Analysis | Identifying whether text expresses positive, negative, or neutral opinion |
🎓 Recommended by CBSE: Continue Learning on IBM SkillsBuild
The CBSE Class 11 AI curriculum recommends completing the “Natural Language Processing” course on IBM SkillsBuild alongside Unit 7.
Why this matters for you: Completing this course counts as your IBM SkillsBuild certification for the Practical File — a mandatory component worth marks in your Class 11 assessment.
👉 Access Natural Language Processing on IBM SkillsBuild →
Free to access. No signup fee. Completing it earns a digital badge you can include in your Practical File.
Practice Questions
Question 1 (2 marks): What is the role of the Lexical Analysis phase in NLP? Give one example.
Model Answer: Lexical analysis is the first phase of NLP. It breaks the input text into individual tokens (words) and identifies the part of speech of each word (noun, verb, adjective, etc.). It also performs stemming and removes stop words. Example: the sentence “She runs daily” is tokenised into [“She”, “runs”, “daily”] and tagged as [Pronoun, Verb, Adverb].
Question 2 (4 marks): Distinguish between Script Bots and Smart Bots. Give two examples of each.
Model Answer:
| Feature | Script Bot | Smart Bot |
|---|---|---|
| Basis | Pre-written rules and patterns | NLP and Machine Learning |
| Flexibility | Only handles programmed inputs | Handles new and varied inputs |
| Learning | Cannot learn from new data | Improves with more data |
| Example | IVR phone menu, Elizabot | Mitsuku, Google Assistant |
Script bots are simpler to build and are suitable for narrow, predictable tasks. Smart bots require NLP training but provide a much more natural conversational experience.
Question 3 (MCQ): Which of the following correctly describes the Semantic Analysis phase of NLP?
(a) It splits text into individual words and removes stop words (b) It checks whether sentences follow correct grammatical rules (c) It interprets the meaning of words and resolves ambiguity (d) It understands the real-world intent and implied meaning behind statements
Answer: (c) — It interprets the meaning of words and resolves ambiguity. (Note: option (d) describes Logical/Pragmatic Analysis, which is Phase 4.)
Frequently Asked Questions
Q1. Is NLP the same as speech recognition? Speech recognition and NLP are related but different. Speech recognition converts spoken audio into text — it handles the sound-to-text step. NLP then processes that text to understand its meaning. When you speak to Siri, speech recognition converts your voice to text, and then NLP figures out what you want. They work together, but they are separate technologies.
Q2. Why does NLP struggle with Hindi or regional Indian languages? Most NLP models were trained primarily on English text available on the internet. Languages like Hindi, Tamil, or Bengali have less digital training data, different grammatical structures (Hindi is verb-final, unlike English), and many dialects. This is exactly why India’s Bhashini project is important — it is building NLP models specifically trained on Indian language data. This is not in your CBSE syllabus but good to know as context.
Q3. What is the difference between Bag of Words and TF-IDF? Both convert text to numerical vectors, but they do it differently. Bag of Words counts raw word frequencies — a word that appears 10 times in a document gets a count of 10. TF-IDF adjusts these counts by penalising words that appear in many documents (like “the” or “is”), because those words are not useful for distinguishing one document from another. TF-IDF is almost always more accurate than plain BoW for classification tasks.
Q4. Dialogflow is used to build chatbots — is it a script bot or a smart bot platform? Dialogflow is a smart bot platform. When you build a chatbot on Dialogflow, you define “intents” (what the user is trying to do) and train the system with example phrases. Dialogflow uses NLP to match new user inputs to the nearest intent — even if the user phrases the question differently from your training examples. This is machine learning in action, not scripted rule-matching.
Q5. Can NLP be a career option after Class 12? Absolutely — and it is one of the fastest-growing areas in AI globally and in India. NLP engineers work on products used by billions of people: search engines, translation tools, virtual assistants, content moderation systems, and medical text analysis. In India, companies like Sarvam AI, AI4Bharat (IIT Madras), Flipkart, and Infosys are actively hiring NLP specialists. The foundation you build in Class 10 and 11 — understanding phases, text processing, and sentiment analysis — is the same conceptual foundation used in professional NLP work.
Action Plan
✅ Exam Practice Checklist
- [ ] Can I define NLP in one sentence and give two India-relevant examples?
- [ ] Can I name and explain all four phases of NLP in order — without looking at notes?
- [ ] Can I write a comparison table of Script Bot vs Smart Bot with four differences?
- [ ] Do I understand what text normalisation includes (at least 3 steps)?
- [ ] Can I explain Bag of Words using a small example with a vocabulary table?
- [ ] Can I explain what problem TF-IDF solves that BoW cannot?
- [ ] Have I completed and documented all three CBSE NLP activities in my Practical File?
🛠 Interactive Tool — Try Live NLP
CBSE Class 10 specifies the Google Cloud Natural Language API as the hands-on tool for keyword extraction. Use it here: 👉 https://cloud.google.com/natural-language
Paste any paragraph — a news headline, a product review, or a sentence from your textbook — and see how the AI identifies entities, analyses sentiment, and extracts syntax in real time.
💡 Project Idea — Hinglish Sentiment Analyser
The idea: Build a simple sentiment classifier that analyses short English or Hinglish (mixed Hindi-English) social media texts and labels them Positive, Negative, or Neutral.
Step 1: Collect 30–40 sample sentences from Twitter/X or product reviews. Label each manually (Positive / Negative / Neutral). This becomes your training dataset.
Step 2: Apply text normalisation (lowercase, remove stop words, tokenise). Represent the text using Bag of Words. Use Orange Data Mining’s Naive Bayes or logistic regression widget to train a classifier on your labelled data.
Step 3: Test with 5 new sentences your model has never seen. Document accuracy, note where it made mistakes, and write why (e.g., sarcasm, unfamiliar words). This is a complete Class 10/11 NLP project suitable for your Practical File.