You have built a machine learning model and tested it. It scores 88% accuracy. But here is the question that separates a good data scientist from a lucky one: Was that 88% a genuine result, or did you just get a lucky split in your data? Model validation techniques exist to answer that question — and they are a core part of CBSE Class 12 AI Unit 2: Data Science Methodology.
What You’ll Learn
- What model validation means and why it is different from simple train-test split
- The three main validation techniques: Holdout, K-Fold, and Leave-One-Out
- When to use each technique and how they connect to your Capstone Project
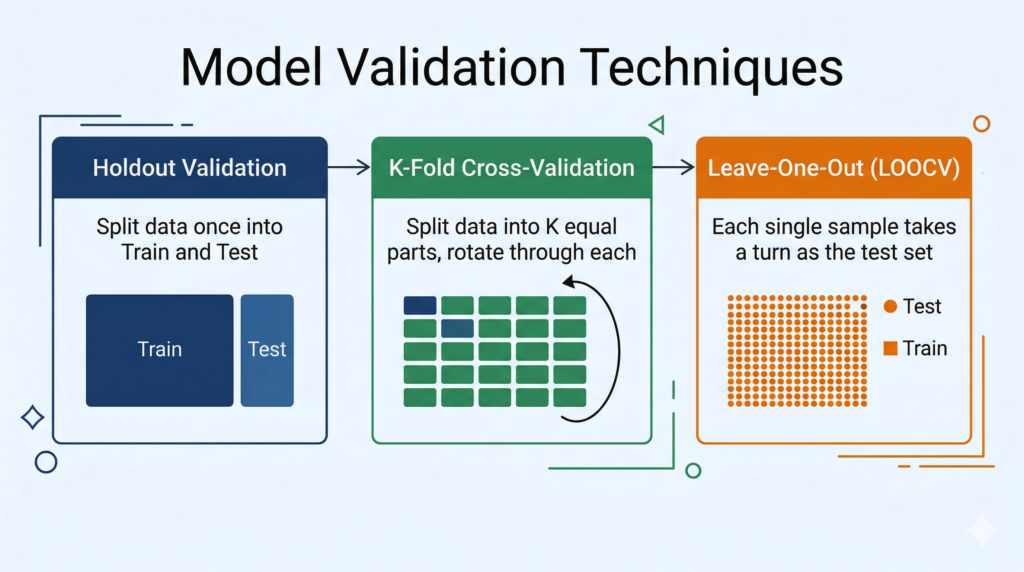
Validation vs Evaluation — What Is the Difference?
Before jumping into techniques, it helps to be clear about two terms that students often confuse.
Model evaluation is what you do after training is complete — you measure the model’s final performance on a held-out test set. This gives you the model’s score that you report. The evaluation metrics you use here include accuracy, precision, recall, F1 score, MSE, and RMSE.
Model validation is what you do during the model-building process — it is the method you use to check whether your model is learning genuine patterns rather than memorising the training data. Validation helps you choose between models, tune settings (called hyperparameters), and catch overfitting before it becomes a problem.
Think of it this way using a manufacturing analogy: validation is the quality check you do during the production line — catching problems before the product ships. Evaluation is the final inspection when the product is finished and about to go to the customer.
📌 CBSE connection: Class 12 Unit 2 (Data Science Methodology) lists “Model Validation Techniques” as an explicit sub-unit with the learning outcome: “Understand the importance of validating machine learning models.”
Technique 1: Holdout Validation
What it is: Divide the dataset into two parts — a training set (typically 70–80%) and a test set (20–30%). Train the model on the training set. Test it on the test set. Report the result.
This is the most straightforward technique and the one you first encounter in Class 10 as train-test split.
How it works:
- Dataset of 1,000 samples
- 800 samples → Training set (model learns here)
- 200 samples → Test set (model is evaluated here)
Advantage: Simple, fast, easy to implement. Good for large datasets where 200 samples is still a meaningful test set.
Limitation: The result depends heavily on which 200 samples ended up in the test set. If those 200 happen to be easier than average, your accuracy looks higher than it really is. If they are harder, it looks lower. One split = one roll of the dice.
When to use it: When your dataset is large (thousands or more samples), holdout validation gives a reliable enough result. For your Class 12 Capstone Project, if you are working with a large public dataset (MNIST, Iris, etc.), holdout is perfectly acceptable.
Technique 2: K-Fold Cross-Validation

What it is: Divide the dataset into K equal parts (called “folds”). Run K separate training-and-testing cycles. In each cycle, one fold is used as the test set and the remaining K−1 folds are used for training. After all K cycles are complete, average the results.
The most common value of K is 5 (5-fold cross-validation) or 10 (10-fold cross-validation).
Step-by-step with K = 5 on a 500-sample dataset:
Each fold = 100 samples.
| Round | Training Set | Test Set | Accuracy |
|---|---|---|---|
| Fold 1 | Folds 2,3,4,5 (400 samples) | Fold 1 (100 samples) | 84% |
| Fold 2 | Folds 1,3,4,5 (400 samples) | Fold 2 (100 samples) | 87% |
| Fold 3 | Folds 1,2,4,5 (400 samples) | Fold 3 (100 samples) | 83% |
| Fold 4 | Folds 1,2,3,5 (400 samples) | Fold 4 (100 samples) | 89% |
| Fold 5 | Folds 1,2,3,4 (400 samples) | Fold 5 (100 samples) | 86% |
Final accuracy = (84 + 87 + 83 + 89 + 86) / 5 = 429 / 5 = 85.8%
Every sample in the dataset gets to be in the test set exactly once. Every sample gets to be in the training set K−1 times. This gives a much more reliable estimate of real-world performance than a single holdout split.
Advantage: More reliable than holdout because it removes the luck factor. Every data point contributes to testing.
Limitation: K times more computationally expensive than holdout — you are training K separate models. For large datasets or complex models, this can be slow.
When to use it: When your dataset is small to medium-sized (a few hundred to a few thousand samples) and reliability matters more than speed. This is the recommended technique for most Class 12 AI Capstone Projects because student datasets are typically not massive.
Technique 3: Leave-One-Out Cross-Validation (LOOCV)
What it is: A special case of K-Fold where K = N (the total number of samples in the dataset). In each round, exactly one sample is used as the test set, and all remaining N−1 samples are used for training. This repeats N times — once for each sample.
Example: Dataset with 100 samples → 100 rounds of training and testing → average 100 accuracy scores.
Advantage: Uses almost all available data for training in every round — the most data-efficient validation technique possible.
Limitation: Extremely slow for large datasets. If your dataset has 10,000 samples, you train 10,000 separate models. Also prone to high variance (individual results can swing a lot from one single-sample test to the next).
When to use it: Only when your dataset is very small (fewer than 50–100 samples) and you cannot afford to lose even a small portion of data for testing. Rarely used in practice for large datasets.
Comparison Table
| Technique | How It Splits | Best For | Limitation |
|---|---|---|---|
| Holdout | One train/test split | Large datasets | Result depends on the random split |
| K-Fold Cross-Validation | K rotations of train/test | Medium datasets (recommended for Capstone) | K× training time |
| Leave-One-Out (LOOCV) | N rounds, 1 sample test each | Very small datasets | Very slow; high variance |
Where Validation Fits in Your Capstone Project
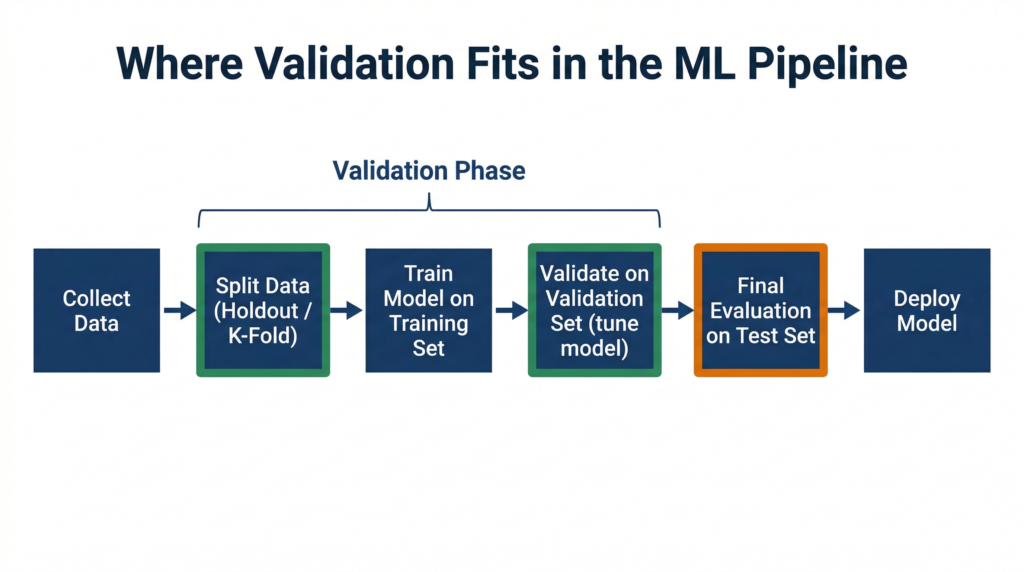
For your Class 12 Capstone Project, model validation is not just a theoretical exercise — it is the process that justifies the accuracy you report in your project documentation.
A common mistake is to train a model, test it once, report the result, and move on. Examiners and viva evaluators will ask: “How did you validate that this accuracy is reliable?”
A strong answer uses K-Fold cross-validation:
- Split your dataset using 5-fold cross-validation
- Record accuracy for each fold
- Report the average accuracy and note the range (e.g., “accuracy ranged from 83% to 89% across 5 folds, with an average of 85.8%”)
- This shows the examiner that your result is stable — it was not a one-off lucky split
This kind of documented validation directly supports your Project Documentation marks (6 marks in the Class 12 practical assessment).
Quick Revision Box
| Term | One-Line Definition |
|---|---|
| Model validation | Checking model performance during building to ensure it learns real patterns |
| Holdout validation | Single train-test split; simple but dependent on random chance |
| K-Fold cross-validation | K rotations of train/test splits; average result is more reliable |
| Leave-One-Out (LOOCV) | Every sample takes a turn as the test set; best for tiny datasets |
| Overfitting | When a model memorises training data and performs poorly on new data |
Practice Questions
Q1 (2 marks): What is K-Fold Cross-Validation? How is it different from simple holdout validation?
Model Answer: K-Fold Cross-Validation is a model validation technique where the dataset is divided into K equal parts (folds). The model is trained and tested K times — in each round, a different fold serves as the test set while the remaining K−1 folds are used for training. The final performance is the average of all K results. Unlike simple holdout validation (which uses a single train-test split), K-Fold reduces dependency on any one particular split of the data, giving a more reliable and unbiased estimate of model performance.
Q2 (MCQ): A Class 12 student is building a Capstone Project with a dataset of 300 samples. Which validation technique is most appropriate?
a) Leave-One-Out Cross-Validation — dataset is too small for anything else b) Holdout Validation with 50/50 split — gives the model equal data to train and test c) 5-Fold Cross-Validation — balances reliability and computational cost ✅ d) No validation needed — the model’s training accuracy is sufficient
Explanation: A 300-sample dataset is medium-sized. 5-Fold Cross-Validation is the best choice because it gives a reliable average result across 5 different splits without being as slow as LOOCV. Holdout with 50/50 wastes training data. LOOCV would require 300 training cycles — unnecessarily slow. Option (d) is always wrong — training accuracy without validation leads to overfitting.
FAQ
Q1: Is validation the same thing as testing? My teacher uses both words.
They are related but refer to different stages. Validation happens during model development — you use it to make decisions about the model (should I use this algorithm or that one? What value of K gives the best result?). Testing happens after the model is finalised — you run it once on a completely held-out test set to get the final reported performance. Good practice keeps the test set completely untouched during all validation work, so the final test result is genuinely unbiased.
Q2: Does Orange Data Mining support cross-validation?
Yes. In Orange’s Test and Score widget, you can choose between “Cross-validation” (which defaults to 10-fold), “Leave-one-out”, and “Train-test split” (holdout). For your practical sessions and Capstone Project work in Orange, selecting “Cross-validation” automatically runs K-Fold validation and reports average results — no manual setup needed.
Q3: Not in your syllabus but good to know — What is stratified K-Fold?
Standard K-Fold splits the data randomly, which can sometimes result in folds with very different class distributions. Stratified K-Fold ensures that each fold has the same proportion of each class as the full dataset. For example, if your dataset has 70% Class A and 30% Class B, every fold will maintain that 70/30 ratio. This is the default in scikit-learn’s StratifiedKFold and gives more reliable results on imbalanced datasets. You will use this in Class 12 Python practicals and beyond.