India has 22 scheduled languages and over 19,500 dialects — but most AI systems understand only English. That gap is not a technical accident. It is an ethics problem, and it is exactly what your Class 11 and Class 12 AI syllabus asks you to think about.

What you’ll learn in this post:
- Why language AI systems like Bhashini carry built-in bias risks
- How to apply the CBSE 4-frame ethics analysis (Stakeholders / Bias / Transparency / Accountability) to a real Indian case
- How to answer CBSE case-based ethics questions using this framework
What Is Bhashini?
Bhashini (officially BHASHINI — भाषिनी) is India’s national language AI platform, launched by the Ministry of Electronics and Information Technology (MeitY) under the IndiaAI Mission. Its goal is straightforward: make digital services accessible to every Indian citizen in their own language.
The platform uses Automatic Speech Recognition (ASR), Machine Translation (MT), and Text-to-Speech (TTS) to allow people to interact with government services, apps, and digital platforms in Hindi, Tamil, Telugu, Kannada, Bengali, Odia, and several other Indian languages — not just English.
Think of Bhashini as the language bridge between India’s government services and its 900+ million non-English-speaking citizens.
Why does this matter for AI ethics?
Because building a language AI for 1.4 billion people across 22 official languages is not just a technical challenge. Every design decision — which language to train first, how much data to collect, whose voice samples to use, how to handle dialects — embeds values. And those values can favour some communities while disadvantaging others.
That is bias at a national scale.
The CBSE 4-Frame Ethics Analysis
Your CBSE AI syllabus requires you to analyse real-world AI systems through four ethical lenses. Here is how each frame applies to Bhashini.
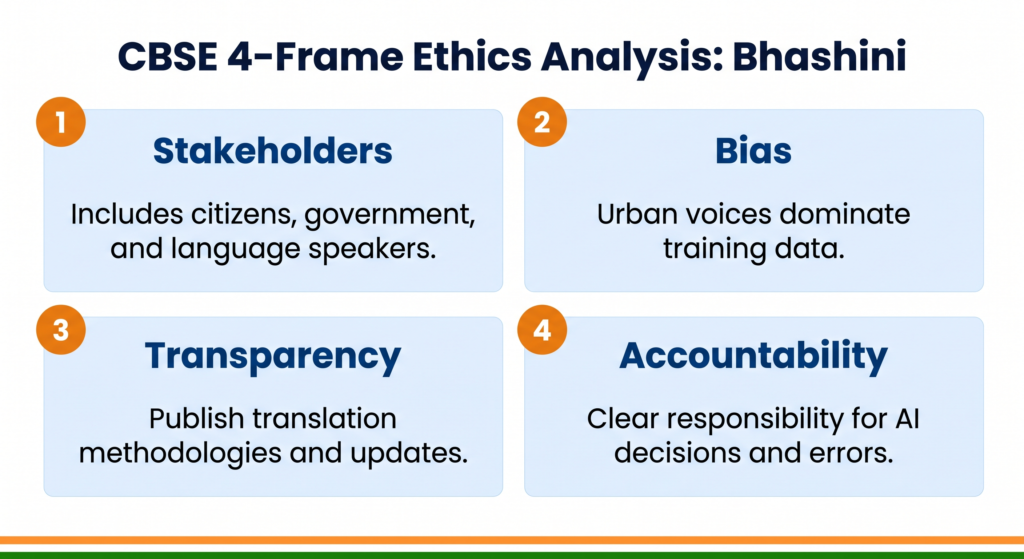
Frame 1 — Stakeholders: Who Is Affected?
A stakeholder is anyone who is affected by an AI system — positively or negatively.
Primary stakeholders in Bhashini:
| Stakeholder | How they are affected |
|---|---|
| Rural citizens (non-English speakers) | Direct beneficiaries — access to e-governance, health, banking in their language |
| Tribal communities (Santali, Gondi, Bodo speakers) | Marginalised — these languages have very little digital training data |
| Women in rural areas | Disproportionately affected by voice-model bias (more on this below) |
| Government agencies (MeitY, UIDAI, DigiLocker) | Operational stakeholders — Bhashini integrates into their service delivery |
| Bhashini dataset contributors | Citizens who volunteered voice samples to train the models |
| Private app developers | Use Bhashini APIs to build multilingual apps |
The stakeholder insight for your exam: Not every stakeholder benefits equally. The people who need Bhashini the most — tribal-language speakers, rural women, elderly citizens — are often the least represented in the training data. This misalignment between “who the system is built for” and “whose data built it” is a classic AI fairness problem.
Frame 2 — Bias: Where Does It Enter?

Bias in language AI can enter at three stages: data collection, model design, and deployment.
Stage 1 — Data bias in Bhashini
Bhashini’s models are trained on voice and text datasets contributed through crowdsourcing campaigns. But crowdsourcing has a participation gap:
- Urban, educated contributors dominate the volunteer pool
- Hindi receives far more data than Santali, Meitei (Manipuri), or Dogri
- Male voices are overrepresented in many ASR datasets globally — and Indian crowdsourced data follows this pattern
The result: Bhashini’s accuracy is demonstrably higher for Hindi and standard urban dialects. A farmer in Vidarbha speaking Varhadi Marathi or a fisherwoman in coastal Odisha speaking Sambalpuri may find the system fails to understand them — even though the platform was launched specifically to serve them.
Stage 2 — Dialect blindness
India does not have 22 neat languages. It has a dialect continuum — Bengali spoken in Sylhet sounds different from the Bengali spoken in Kolkata. Bhashini’s models, like most language AI systems, are trained on standardised written forms of languages. Dialects, code-switching (mixing Hindi and English mid-sentence), and regional accents often produce recognition errors.
Stage 3 — Script and transliteration bias
Several Indian languages (Dogri, Kashmiri, Sindhi) are written in multiple scripts depending on region. A model trained primarily on one script version will fail users of the other. This is not a minor edge case — it determines whether whole communities can use the system.
The exam-ready definition: Bias in language AI occurs when training data does not represent all user groups equally, causing the system to perform better for some communities than others.
Frame 3 — Transparency: Can Users Understand the System?
Transparency asks: does the system explain how it works, who built it, and why it makes the decisions it does?
What Bhashini does well on transparency:
- The platform is open-source — developers can inspect the models and APIs
- MeitY publishes dataset collection guidelines publicly
- The Bhashini portal lists supported languages and model accuracy benchmarks
Where transparency gaps remain:
- Accuracy benchmarks are reported at the language level — not broken down by dialect, age group, or gender. A rural woman speaking a regional dialect has no way to know the system’s actual accuracy for her speech pattern.
- When Bhashini produces an incorrect translation or misrecognises a voice input in a government service context, there is no visible explanation or error-flag for the user. The citizen simply receives wrong information — without knowing it is wrong.
- The datasets used to train models include crowdsourced contributions, but the governance of who reviews these contributions and how quality is maintained is not publicly visible at a granular level.
Key transparency principle for CBSE: An AI system is transparent if affected users can understand what data was used, how decisions are made, and what to do when the system is wrong.
Frame 4 — Accountability: Who Is Responsible?
Accountability asks: when the system causes harm, who is answerable, and what is the process for redress?
The accountability challenge in Bhashini:
Bhashini operates as a government-to-citizen infrastructure layer. Multiple actors are involved — MeitY (policy), the AI4Bharat research team (model development), private API developers (app deployment), and end-users. When a citizen receives incorrect medical information because Bhashini mis-translated a government health advisory, accountability is fragmented:
- Was it the model’s training data that failed?
- Was it the app developer’s implementation?
- Was it MeitY’s quality assurance process?
This chain of accountability is common in AI systems built on shared infrastructure — and it is a gap your CBSE syllabus explicitly asks you to identify.
A positive development worth noting: India’s Digital Personal Data Protection Act 2023 (DPDPA) requires data processors handling citizen data to implement safeguards and report breaches. Bhashini’s dataset collection — which involves voice recordings — falls under this framework. This is an early step toward accountability, though enforcement mechanisms specific to AI performance failures are still evolving.
Real-World Implications: Who Gets Left Behind?
The ethics of Bhashini is not abstract. Here are concrete examples of the inclusion gap:
Healthcare access: Bhashini is integrated into Ayushman Bharat’s digital health services. If a tribal-language speaker cannot accurately query their health records or understand a translated medical advisory, the bias has a direct health consequence.
Banking exclusion: Jan Dhan account holders in rural areas using Aadhaar-linked banking services via voice interfaces depend on accurate speech recognition. Recognition errors can lock users out of accounts or trigger incorrect transactions.
Education: Bhashini is being integrated into DIKSHA (Digital Infrastructure for Knowledge Sharing) to deliver learning materials in regional languages. If a Class 6 student in Manipur hears a mis-translated science lesson, the bias has entered the classroom.
The SDG connection: This directly connects to SDG 10 (Reduced Inequalities) — which your CBSE AI syllabus references. A language AI that works only for Hindi-speaking urban users deepens the digital divide rather than closing it.
What Responsible Language AI Looks Like
Identifying bias is only the first step — your CBSE exam often asks you to suggest solutions. Here is a structured response framework:
| Problem | Responsible AI Response |
|---|---|
| Underrepresented dialects in training data | Targeted data collection in tribal and rural communities, with community consent |
| Gender imbalance in voice samples | Quota-based crowdsourcing — ensure gender-balanced contributions per language |
| No error feedback for users | Add a simple “Was this translation correct?” prompt with a correction mechanism |
| Fragmented accountability | Publish a clear accountability matrix — who is responsible for model performance vs. app deployment vs. policy |
| Lack of dialect-level benchmarks | Publish accuracy metrics broken down by dialect, region, age group, and gender |
Quick Revision Box
| Term | Meaning |
|---|---|
| Bhashini | India’s national AI platform for multilingual access to digital services (MeitY) |
| ASR | Automatic Speech Recognition — converting spoken language to text |
| Data bias | When training data does not equally represent all user groups |
| Transparency | Users can understand how the AI makes decisions and what data it uses |
| Accountability | Clear responsibility for harm caused by AI decisions |
Practice Questions
2-mark question: Identify two stakeholder groups who may be negatively affected by bias in Bhashini’s speech recognition system, and give one reason for each.
Model answer: Tribal-language speakers are negatively affected because their languages (such as Santali or Gondi) have very little training data, causing higher error rates. Rural women are negatively affected because voice training datasets often overrepresent male urban speakers, reducing accuracy for female regional voices.
MCQ: Which of the following best describes “transparency” in an AI system like Bhashini?
(A) The system is built by a government agency (B) Users can understand what data was used, how decisions are made, and how to report errors (C) The system works in more than ten languages (D) The system’s source code is written by Indian researchers
Answer: (B)
FAQ
Q1. Is Bhashini only useful for government services? No. Bhashini’s APIs are publicly available to private developers as well. Apps built on Bhashini can offer multilingual chat support, voice-based interfaces, and translation features across sectors including education, healthcare, and retail. The ethics analysis in this post applies to all of these use cases, not just government services.
Q2. How is Bhashini different from Google Translate? Google Translate is a proprietary global product optimised for international languages. Bhashini is specifically designed for Indian languages, including those Google Translate does not support well, and it is open-source, meaning researchers and developers can inspect and improve the underlying models. However, open-source does not automatically mean bias-free — the same ethical questions about training data and accountability still apply.
Q3. Can this Bhashini case study appear in my CBSE board exam? Yes — and it is a high-value case study to know. CBSE’s 2025-26 AI sample papers include case-based ethics questions for Class 11 and Class 12. Any real-world Indian AI system is fair game. Applying the four-frame structure (Stakeholders / Bias / Transparency / Accountability) to Bhashini gives you a complete, CBSE-aligned answer template you can adapt to any case study question.