You have used ChatGPT or Google Gemini at least once. But when your Class 12 AI exam asks you to explain what a Large Language Model is, most students write one vague sentence and move on. That costs marks. This post gives you the complete, exam-ready explanation of LLMs — what they are, how they work, and why CBSE included them in your syllabus.
What You’ll Learn
- What a Large Language Model (LLM) is and how CBSE defines it
- How LLMs are trained and why scale matters
- Real-world LLM applications you already use
- How to answer 2-mark and 4-mark exam questions on this topic
What Is a Large Language Model?
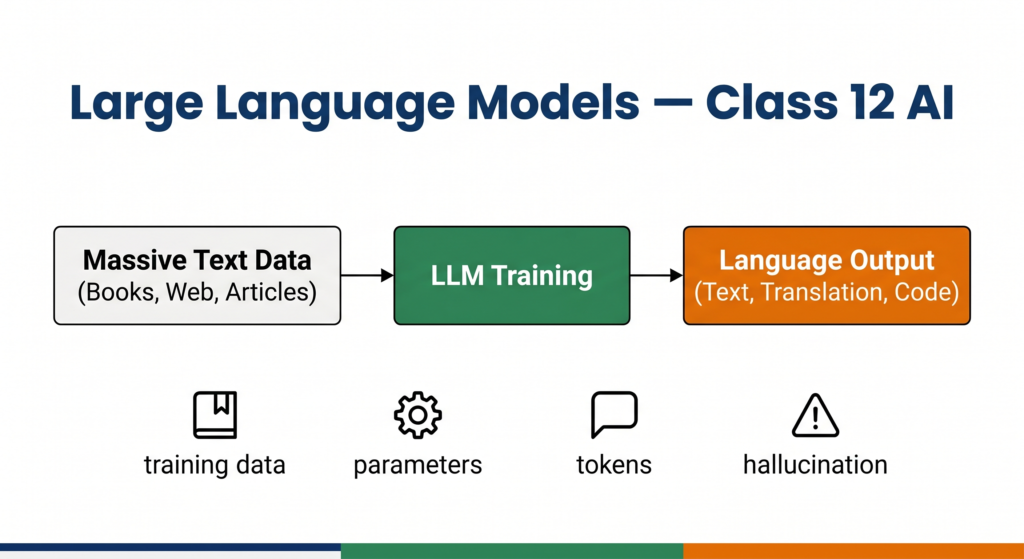
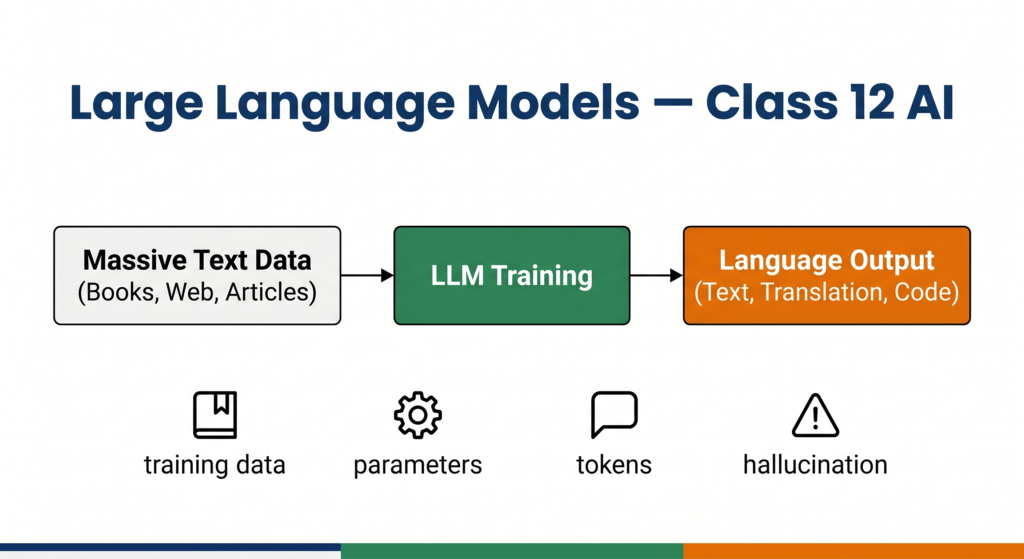
A Large Language Model (LLM) is a type of AI model trained on massive amounts of text data to understand, generate, and manipulate human language. The word “large” refers to two things: the enormous volume of training data (billions of sentences from books, websites, and articles) and the enormous number of parameters inside the model (sometimes hundreds of billions of adjustable values that the model learns during training).
LLMs are a sub-type of Generative AI — specifically, they generate text. Given a prompt (your input), an LLM predicts and produces a coherent, contextually relevant response.
CBSE Class 12 Unit 7 explicitly lists LLM — Large Language Model as a named sub-unit under Generative AI. Expect a 2-mark or 4-mark definition question in your theory paper.
Simple definition to memorise for exams:
A Large Language Model is an AI system trained on large-scale text data that can understand and generate human language by predicting the most likely next word or sequence of words based on context.
How Does an LLM Work?
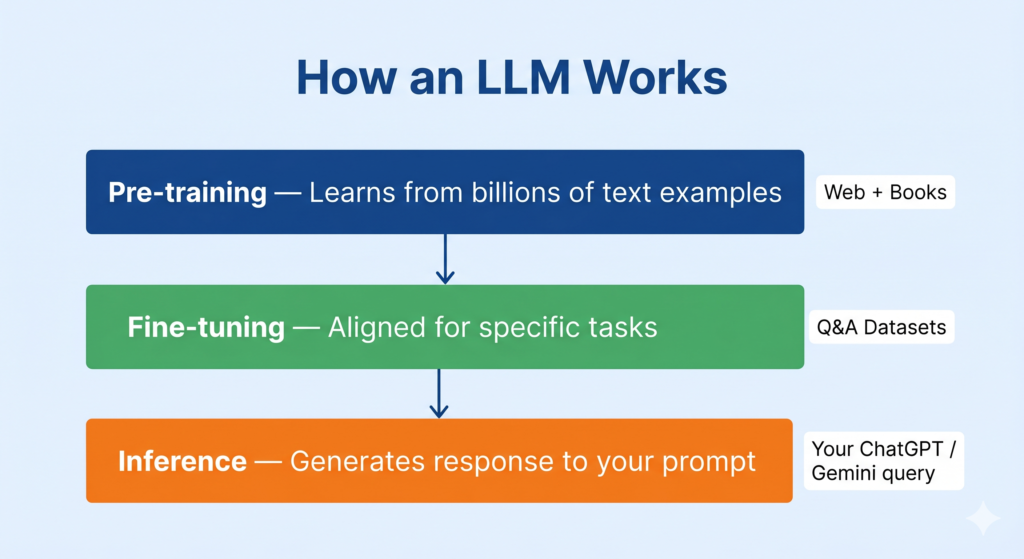
Understanding how an LLM works helps you answer “explain the working of” questions confidently. Here is the process broken into three stages.
Stage 1 — Pre-training on Massive Text Data
The model is exposed to billions of sentences from the internet, books, code repositories, and research papers. During this stage, it learns patterns — how words relate to each other, how sentences are structured, what topics connect to what concepts. This is unsupervised learning at a scale that was not possible before modern computing hardware.
India’s own text AI initiative, Bhashini (under the IndiaAI Mission), works on similar principles — training language models specifically on Indian languages including Hindi, Tamil, Bengali, and others, to make AI accessible across India’s linguistic diversity.
Stage 2 — Fine-tuning for Specific Tasks
After pre-training, the model is further trained on smaller, carefully curated datasets to align its outputs with specific goals — for example, answering questions helpfully, following instructions, or refusing harmful requests. This step is called fine-tuning. Models like ChatGPT (by OpenAI) and Gemini (by Google) both went through extensive fine-tuning after their initial pre-training.
Stage 3 — Inference (Using the Model)
When you type a prompt into ChatGPT or Gemini, the model processes your input token by token (a token is roughly a word or part of a word) and generates a response by predicting the next most likely token at each step. This is called inference. The model does not “think” the way humans do — it is performing highly sophisticated pattern matching across the language patterns it learned during training.
Key Components of an LLM
| Component | What It Does |
|---|---|
| Tokens | The units the model processes — roughly words or word-fragments |
| Parameters | Adjustable numerical values learned during training; more parameters = more capacity |
| Context window | How much text the model can “see” at one time when generating a response |
| Transformer architecture | The underlying neural network design that makes LLMs efficient at handling sequences |
| Prompt | The input you give to the model — quality of prompt directly affects quality of output |
Popular LLMs You Should Know

Your CBSE activities explicitly require you to explore ChatGPT and Google Gemini. Here are the key models to know for exams and practicals.
ChatGPT (OpenAI) — One of the first LLMs to become widely used by the public. Built on the GPT (Generative Pre-trained Transformer) family of models. Your CBSE PDF specifically mentions using ChatGPT for conversational text generation and creative tasks.
Google Gemini — Google’s multimodal LLM that can handle text, images, and code. Your CBSE PDF requires you to use Gemini to craft prompts and generate text outputs. The Gemini API is the basis of the chatbot activity in Unit 7.
Bhashini (India) — India’s national language AI platform developed under the IndiaAI Mission. It uses LLM-based models fine-tuned for Indian languages to enable speech-to-text, translation, and text generation across 22 scheduled languages. It is the most relevant Indian example for exam answers.
BERT (Google) — An earlier transformer-based model. Unlike GPT-style models that generate text left to right, BERT reads the entire sentence at once, making it excellent for tasks like question answering and classification.
Applications of LLMs
LLMs are not just chatbots. Here are applications you should be able to name in a 4-mark answer.
Text generation — Writing emails, summaries, articles, and creative content. Tools like Canva’s AI writing features (which CBSE asks you to explore) use LLM-based engines.
Code generation — LLMs like GitHub Copilot can suggest and complete Python code, which is directly relevant to your Class 12 AI practicals.
Translation — Bhashini uses LLM-based systems to translate between Indian languages, supporting government services and digital inclusion.
Question answering — LLMs power AI tutors, customer service bots, and search assistants. The CBSE-specified activity of using Google Gemini to answer questions is a direct application of this.
Content moderation — Social media platforms use LLMs to detect harmful, misleading, or abusive content at scale.
Healthcare — Hospitals and health platforms use LLMs to summarise patient records, assist with diagnosis research, and generate medical reports.
Limitations and Ethical Concerns
CBSE Unit 7 explicitly includes Ethical and Social Implications of Generative AI as a sub-unit. Questions on limitations are common in theory papers.
Hallucination — LLMs can generate text that sounds confident but is factually wrong. The model does not “know” facts — it predicts patterns. This is a major concern when using LLMs for medical, legal, or academic purposes.
Bias in training data — If the training data contains biased language (racist, sexist, or culturally skewed text), the model will reproduce those biases in its outputs. This is why CBSE’s ethics sub-unit is paired directly with Generative AI.
Copyright and intellectual property — LLMs trained on books, articles, and code raise questions about whether the outputs infringe on original authors’ work.
Environmental cost — Training a large LLM consumes enormous computing power and electricity, raising sustainability concerns.
Misinformation — LLMs can be used to generate fake news, deepfake scripts, and misleading content at scale.
Try It Yourself — CBSE Activity
Your CBSE Class 12 Unit 7 requires hands-on exploration of LLMs. Here is how to complete this activity for your practical file.
Activity: Explore ChatGPT and Google Gemini for Text Generation
Step 1 — Go to chat.openai.com and create a free account (or use an existing one). Give ChatGPT the prompt: “Explain what a Large Language Model is in simple terms for a Class 12 student.” Observe how it structures its response.
Step 2 — Go to gemini.google.com. Give Gemini the same prompt and compare the two responses. Note which response is more accurate and which is easier to read.
Step 3 — Now try a creative task on Gemini: “Write a short poem about how AI is changing education in India.” Note how the model generates text that was never in its training data explicitly but is assembled from learned patterns.
Step 4 — Document in your practical file: the prompts you used, the responses received, one similarity and one difference between ChatGPT and Gemini, and one hallucination or factual error you noticed (if any).
What to note for your practical file: Screenshots of at least two prompt-response exchanges. A 3–4 line reflection on what surprised you about how the model responded.
Common Exam Mistakes
Mistake 1 — Calling LLMs “just chatbots” Chatbots existed before LLMs and used simple rule-based logic. LLMs are far more sophisticated — they understand context, generate novel text, and handle complex instructions. In your exam answer, always specify that LLMs are trained on large-scale data and use transformer architecture.
Mistake 2 — Confusing parameters with data Parameters are the internal learned values inside the model (like the knobs on a machine). Training data is the text the model was exposed to. These are different things. Do not write “an LLM has billions of training data” — write “an LLM has billions of parameters.”
Mistake 3 — Saying LLMs “understand” language Technically, LLMs predict statistically likely outputs — they do not understand meaning the way humans do. In an ethics or critical thinking question, this distinction matters. Use phrases like “appears to understand” or “processes and generates language.”
Mistake 4 — Forgetting Indian examples Examiners in CBSE vocational AI appreciate India-relevant content. Always mention Bhashini or IndiaAI Mission when answering questions about LLM applications in the Indian context.
Exam Strategy
For a 2-mark question (“Define LLM” or “What is a Large Language Model?”): Write exactly two points: (1) what it is trained on, and (2) what it can do. Example: “A Large Language Model (LLM) is an AI model trained on large volumes of text data to understand and generate human language. It predicts the next most likely word based on context and can perform tasks such as text generation, translation, and question answering.”
For a 4-mark question (“Explain how LLMs work with examples”): Structure your answer in three parts: definition (1 mark), working/stages (2 marks), examples (1 mark). Use ChatGPT, Gemini, and Bhashini as your three examples.
For a question on ethical concerns: CBSE expects you to cover at least two concerns. Pick hallucination and bias — these are the most examinable because they are explicitly named in the Unit 7 learning outcomes.
Quick Revision Box
| Term | Meaning |
|---|---|
| LLM | AI model trained on massive text data to understand and generate language |
| Token | Unit of text the model processes (roughly a word or word-fragment) |
| Parameter | Numerical value learned during training; more parameters = higher capacity |
| Hallucination | When an LLM confidently generates factually incorrect information |
| Fine-tuning | Training the model further on a smaller task-specific dataset after pre-training |
| Transformer | Neural network architecture underlying modern LLMs |
| Bhashini | India’s national language AI platform using LLM-based multilingual models |
Practice Questions
2-mark question: What is a Large Language Model? Name one LLM used in your CBSE Class 12 AI practicals.
Model answer: A Large Language Model is an AI system trained on large-scale text data to generate and understand human language by predicting the next word based on context. Google Gemini is an LLM used in CBSE Class 12 Unit 7 practicals for generating text outputs from prompts.
MCQ: Which of the following best describes a “hallucination” in the context of LLMs?
(A) The model refuses to answer a question (B) The model generates factually incorrect information confidently (C) The model takes too long to respond (D) The model cannot understand the prompt
Answer: (B) — Hallucination refers specifically to the model producing incorrect but confident-sounding outputs.
FAQ
Q1. Is LLM in the Class 12 AI theory paper or only practicals? LLM is listed as a named sub-unit under Unit 7: Generative AI in Part B. Unit 7 carries 7 theory marks in Class 12. Expect at least one question from this sub-unit in your theory paper — typically a 2-mark definition or a 4-mark explanation.
Q2. Do I need to know Python to use an LLM for my practicals? The core CBSE Unit 7 activities — exploring ChatGPT, Gemini, Canva, and Animaker — require no Python coding. The Gemini API chatbot activity is marked “For Advanced Learners” in the CBSE PDF and will not appear in your theory or practical examination unless your school specifically assigns it.
Q3. How is an LLM different from a search engine? A search engine retrieves existing web pages that match your query. An LLM generates new text by predicting word sequences based on patterns learned during training. A search engine finds; an LLM creates. This distinction is a common 2-mark question in boards.
Q4. Why does CBSE include LLMs in Class 12 when the technology is so new? The 2025-26 CBSE syllabus for Class 12 AI was updated specifically to include Generative AI and LLMs because these technologies are now part of everyday professional life. CBSE’s stated learning outcome for Unit 7 is that students should be able to “gain hands-on experience using AI tools to generate creative and analytical outputs.” Understanding LLMs prepares you for careers in tech, content, healthcare, finance, and virtually every other sector.
Q5. Are LLMs the future of AI, or will something replace them? LLMs currently represent the most capable publicly accessible AI systems for language tasks. Researchers are already exploring multimodal models (handling text, image, audio, and video together), smaller and more efficient models (like those running on mobile devices), and models with better reasoning. Whether LLMs get replaced or evolved, the core concepts — training data, parameters, context, and ethical implications — will remain relevant for any AI professional.